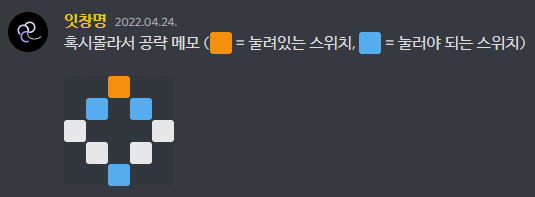
글 작성 이후에도 dlaud5379 명의로 다른 문제를 출제할 때마다 업데이트할 예정입니다.
CPC 2020
2020 중앙대학교 프로그래밍 경진대회에 한 문제를 출제하고, 두 문제에 삽화를 제공했습니다.
20210번 "파일 탐색기" (F번)
문제
Windows의 파일 탐색기를 보면 파일이 정렬된 방식이 보통의 정렬 방식과는 다른 것을 알 수 있다. 보통 문자열을 정렬할 때는 맨 앞부터 한 글자씩 비교하다가 어느 한쪽이 끝나거나 일치하지 않는 글자가 있으면 그 위치의 문자를 비교한 결과가 문자열 전체를 비교한 결과가 된다. 한편 파일 탐색기는 여러 자리의 수를 한 글자로 취급해서 비교하는데, 이 때문에 "
str12ing"과 "str123ing" 중 후자가 아니라 전자가 앞에 온다. 이러한 정렬 방식을 종종 "natural sort"라고 하기도 한다. 여러 개의 문자열이 주어지면 natural sort 방식으로 정렬한 결과를 출력하는 프로그램을 작성해 보자. 이 문제에서 구현할 알고리즘은 다음을 만족해야 한다.
- 문자열은 알파벳 대소문자와 숫자로만 이루어져 있다.
- 숫자열이 알파벳보다 앞에 오고, 알파벳끼리는 AaBbCc...XxYyZz의 순서를 따른다.
- 문자열을 비교하는 중 숫자가 있을 경우 그 다음에 오는 숫자를 최대한 많이 묶어 한 단위로 비교한다. 예를 들어 "
a12bc345"는 "a", "12", "b", "c", "345"의 다섯 단위로 이루어져 있다.- 숫자열끼리는 십진법으로 읽어서 더 작은 것이 앞에 온다. 이때 예제 2에서와 같이 값이 \(2^{63}\)을 초과할 수 있다.
- 같은 값을 가지는 숫자열일 경우 앞에 따라붙는 0의 개수가 적은 것이 앞에 온다.
입력
첫 줄에 문자열의 개수 N(2 ≤ N ≤ 10,000)이 주어진다. 그 다음 N줄에 정렬할 문자열이 한 줄에 하나씩 주어진다. 모든 문자열의 길이는 100 이하이며, 알파벳 대소문자와 숫자로만 이루어져 있다.
출력
N줄에 걸쳐 문제에서 설명한 대로 문자열을 정렬한 결과를 출력한다.
예제 입력 1
8 Foo1Bar Foo12Bar Foo3bar Fo6Bar Foo00012Bar Foo3Bar foo4bar FOOBAR예제 출력 1
FOOBAR Fo6Bar Foo1Bar Foo3Bar Foo3bar Foo12Bar Foo00012Bar foo4bar예제 입력 2
5 1234567890123456789012345678901234500500 1234567890123456789012345678901234500000 1234567890123456789012345678901234506000 1234567890123456789012345678901234500002 1234567890123456789012345678901234530000예제 출력 2
1234567890123456789012345678901234500000 1234567890123456789012345678901234500002 1234567890123456789012345678901234500500 1234567890123456789012345678901234506000 1234567890123456789012345678901234530000
2024년 9월 2일 현재 이 문제의 난이도는 골드 3이며, 알고리즘 분류는 #구현 #정렬 #문자열입니다. 출제 이후 거의 4년이 지난 지금(2024년 2월 8일) 구글에 백준 20210으로 검색해 봤더니 생각보다 이 문제에 대한 블로그 글이 많네요. 풀어주셔서 감사합니다 🙇
지문에서 짐작할 수 있듯이 표준 라이브러리에서 제공하는 정렬 함수에 비교 함수를 만들어 호출하면 되는 정직한 문제입니다. 물론 그 비교 함수 구현이 좀 복잡하긴 합니다. 비교 함수의 조건을 간단하게 요약하면 이렇습니다.
- 숫자는 무조건 문자보다 작다.
- 문자끼리 비교
- 대소문자 구분 없이 사전순으로 비교하고,
- 같은 문자라면 대문자가 소문자보다 작다.
- 숫자끼리 비교
- 최대한 긴 숫자열로 묶는다.
- 십진법으로 읽은 값으로 비교하고,
- 같은 값이라면 불필요한 0이 적을수록 작다.
제가 의도한 C++14 풀이(정답자만 열람 가능합니다)에서 비교 함수의 전체적인 구조는 이렇습니다. 입력 문자열의 길이 \(n\)에 대해 비교 함수의 시간 복잡도는 \(O(n)\)입니다.
// 좌변이 작으면 음수, 우변이 작으면 양수, 같으면 0
int 문자끼리_비교(char 좌변, char 우변) {
if(대문자로 변환한 좌·우변이 다름)
return (대문자로 변환한 좌변이 다르면 -1, 아니면 1);
return (좌·우변의 대문자 여부만 추출해서 비교);
}
// 좌변이 우변 미만이어야 `true`
bool 비교함수(const string &좌변, const string &우변) {
while(좌·우변을 첫 글자부터 스캔하면서) {
if(우변이 일찍 끝남)
return false;
if(좌변이 일찍 끝남)
return true;
if(좌·우변의 숫자/문자 여부가 다름)
return (좌변이 숫자인지 여부);
if(좌·우변이 문자) {
// 문자끼리 비교
int 비교결과 = 문자끼리_비교(현재 좌·우변에서 스캔하는 글자);
if(비교결과 != 0)
return 비교결과 < 0;
} else {
// 숫자열끼리 비교
// 값으로 비교
if(좌·우변에서 불필요한 0을 뺀 길이가 다름)
return (불필요한 0을 뺀 좌·우변의 문자열 길이끼리 비교);
int 비교결과 = (불필요한 0을 뺀 좌·우변을 사전식으로 비교);
if(비교결과 != 0)
return 비교결과 < 0;
// 불필요한 0의 개수로 비교
if(좌·우변의 불필요한 0의 개수가 다름)
return (좌·우변의 불필요한 0의 개수로 비교);
// 두 숫자열이 일치함
}
}
}
CHAC 2022
ChAOS Hello 2022 Algorithm Content에 두 문제를 출제하고, 세 문제에 삽화를 제공했습니다.
CPC 2020에 문제를 출제할 때 지문에 "잇창명"을 넣지 않은 게 후회되어서 이번에 출제하는 두 문제에는 모두 "잇창명"을 넣었습니다.
24390번 "또 전자레인지야?" (D번)
문제
잇창명의 집에는 오래된 전자레인지가 있다. 백준 온라인 저지에서 문제를 너무 많이 푼 잇창명은 문득 이런 궁금증이 생기기 시작했다.
버튼을 최소 몇 번 눌러야 조리시간 2분을 맞출 수 있을까?
잇창명의 전자레인지에는 다음과 같이 버튼이 4개 있고, 각 버튼을 누르면 다음과 같이 작동한다. 초기 상태에는 조리시간이 0초이고, 조리 중이 아니며, 조리시작 버튼을 눌러야 조리가 시작된다.
- 10초: 조리시간이 10초 늘어난다.
- 1분: 조리시간이 1분(60초) 늘어난다.
- 10분: 조리시간이 10분(600초) 늘어난다.
- 조리시작
- 조리 중이 아닐 때: 조리가 시작된다. 만약에 조리시간이 0초였다면 30초로 늘어난다.
- 조리 중일 때: 조리시간이 30초 늘어난다.
- 모든 버튼은 조리 중인지의 여부와 무관하게 항상 누를 수 있으며, 별도의 언급이 없을 경우 항상 같은 동작을 한다.
예를 들어 이 전자레인지로 2분을 맞추려면 조리시작 버튼을 4번 누르면 되지만, 최적의 방법은 아니다. 그 대신 1분-1분-조리시작 순서로 버튼을 누르면 버튼을 누른 횟수가 3번이 되어 최적이다. 1분-1분의 경우에는 조리가 되지 않기 때문에 최적이 아니다. 실제로는 조리 중에는 남은 조리시간이 계속 줄어들고 중간에 조리를 취소할 수 있지만, 이 문제에서는 생각하지 않기로 한다.
잇창명은 지난 한 학기 동안 전자레인지를 이용할 때마다 매번 문제로 내고 싶은 마음이 들어서 괴로워하고 있다. 잇창명을 도와주자!
입력
첫 줄에 잇창명이 원하는 조리시간이
M:S형태로 주어진다(0 ≤ M ≤ 60, 0 ≤ S ≤ 59). M은 분, S는 초이며, 항상 두 자리 숫자로 주어진다.조리시간은 10초 이상 60분(3600초) 이하이며, 항상 10의 배수이다.
출력
주어진 조리시간을 맞추기 위해 버튼을 눌러야 하는 최소 횟수를 출력한다.
예제 입력 1
02:00예제 출력 1
3
2024년 9월 2일 현재 이 문제의 난이도는 실버 2이며, 알고리즘 분류는 #그리디 알고리즘입니다.
처음 출제했을 때는 탐욕법과 너비 우선 탐색만을 정해로 생각했는데, 문제 검수 중에 동적 계획법으로 풀 수 있다는 것을 알게 되어 결과적으로는 정해가 사실상 3개인 문제가 되었습니다. 개인적으로 좋은 문제가 되었다고 생각해 꽤 만족스럽네요.
너비 우선 탐색
가장 직관적으로 떠오를 만한 풀이입니다. 조리시간(int)과 조리 여부(bool)의 순서쌍을 정점으로, 각 버튼마다 가능한 상태 변화를 유향 간선으로 삼고 \((0, \mathrm{false})\) 노드에서 출발하는 너비 우선 탐색을 할 수 있습니다.
탐욕법
제가 처음 의도했던 C11 풀이이기도 합니다(정답자만 열람 가능합니다). 당시 Gather에서 공개했던 에디토리얼에 탐욕법에 대한 증명을 실었었는데, 대중에 공개된 링크를 못 찾겠네요. 이 블로그에는 좀 더 엄밀하게 다듬은 증명을 싣겠습니다.
30초 버튼의 특수한 성질을 무시하고 문제를 풀면 30초 버튼을 정확히 0번 혹은 1번 누를 수 있습니다(30초 다음 단위가 60초이므로).
- 30초 버튼을 1번 누르는 경우: 30초 버튼을 가장 처음에 누르면 정상적으로 30초가 추가되면서 조리가 시작되므로 일반적인 탐욕법과 같은 해를 가집니다.
- 30초 버튼을 누르지 않는 경우: 이때는 조리가 시작되지 않으므로 어떻게든 30초 버튼을 추가로 눌러야 합니다. 편의상 추가로 버튼을 누르는 횟수를 \(n\)이라고 하겠습니다.
- 모든 경우에 대해 \(n=1\)인 알고리즘이 존재합니다.
- 모든 버튼을 누르고 나서 30초 버튼을 마지막에 추가로 누를 수 있는데, 아직 조리가 시작되지 않았으므로 조리가 시작되고 원래 조리시간이 0이 아니었으므로 조리시간은 유지됩니다.
- 탐욕법의 성질에 의해 \(n \le 0\)일 수는 없습니다.
- 위의 논리에 의해 일반적인 탐욕법으로 구한 해에 \(n=1\)을 더한 것이 해가 됩니다.
- 모든 경우에 대해 \(n=1\)인 알고리즘이 존재합니다.
추가로 입력 범위가 작은 것을 이용해 너비 우선 탐색 코드와 탐욕법 코드가 모든 입력에 대해 같은 출력을 하는지 체크하는, 말 그대로 "proof by AC"1를 했습니다.
동적 계획법
위의 너비 우선 탐색 풀이를 그대로 동적 계획법으로 바꿀 수 있습니다. 조리시간 i와 조리 여부 j에 대해 dp[i][j]를 만들고 풀면 됩니다.
24394번 "123456789점" (G번)
문제
잇창명은 취미로 리듬 게임을 한다. 위에서 내려오는 노트를 정확한 타이밍에 처리하면 높은 점수를 얻을 수 있다.
노트를 처리하면 각각 다음 판정 중 하나를 받을 수 있다.
- Perfect
- Great
- Good
- Miss
노트를 처리하지 못하면 Miss 판정을 받는다. 위 4가지 판정 이외에 다른 판정은 없다. 노트가 N개 있는 곡에서 Perfect 판정을 a개, Great 판정을 b개, Good 판정을 c개 받았을 때의 점수는 다음 식으로 계산한다. 소숫점 아래는 버린다.
\(\biggl\lfloor {10^9 \times \frac{2a + 2b + c}{2N} + a} \biggr\rfloor\)
다시 말해, Good 판정의 점수인 \(\frac{10^9}{2N}\)을 기준으로 각 판정의 점수는 다음과 같다.
- Perfect = 2 Good + 1
- Great = 2 Good
- Good = 1 Good
- Miss = 0
예를 들어 노트가 100개 있는 곡에서 Perfect를 10개, Great를 20개, Good을 30개 받으면 450,000,010점을 획득한다. 이때 최고 점수는 Perfect 판정만을 N개 받았을 때 \(10^9 + N\)점이 된다.
잇창명은 이 게임에서 정확히 123,456,789점을 획득해 사람들을 놀라게 하고 싶다. 잇창명은 초고수 플레이어라서 모든 노트의 판정을 원하는 대로 조절할 수 있다. 잇창명이 연주하려는 곡의 노트 수가 주어질 때, 잇창명이 이 곡을 어떻게 연주해야 원하는 점수를 획득할 수 있을지 계산하는 프로그램을 작성하시오.
입력
첫 줄에 테스트 케이스의 수 T(1 ≤ T ≤ 2,000)가 주어진다. 다음 줄부터는 T개의 테스트 케이스가 주어진다.
각 테스트 케이스에서는 한 줄에 노트의 개수 N(1 ≤ N ≤ 20,000)과 잇창명이 원하는 점수 S(0 ≤ S ≤ 109+N)가 공백으로 구분되어 주어진다. N과 S는 정수이다.
출력
각 테스트 케이스마다 한 줄에 걸쳐 다음을 출력한다.
- 잇창명이 Perfect 판정을 a개, Great 판정을 b개, Good 판정을 c개 받아서 정확히 S점을 획득할 수 있다면 2a+2b+c와 a를 공백으로 구분하여 출력한다. 가능한 (2a+2b+c, a)의 쌍이 여러 개인 입력은 없다.
- 잇창명이 곡을 어떻게 연주해도 정확히 S점을 획득할 수 없다면
-1을 출력한다.예제 입력 1
3 1000 1000001000 4318 899954000 20000 123456789예제 출력 1
2000 1000 7772 318 -1
2024년 9월 2일 현재 이 문제의 난이도는 골드 3이며, 알고리즘 분류는 #수학입니다. 원래 \(O(T)\)를 의도한 문제라서 난이도 의견에 "\(O(TN)\)이 [출제자의] 의도"라는 말을 보고 깜짝 놀랐습니다.
소재와의 연관성
제가 남긴 solved.ac 난이도 의견에서 볼 수 있듯이 이 문제의 소재는 실존하는 리듬 게임인 Arcaea, 특히 점수 체계입니다. 특히 문제에서 제시한 판정 체계는 실제 게임의 판정 체계를 더욱 대중적인 용어로 바꾼 것입니다.
- Perfect = Shiny PURE
- Great = Early/Late PURE
- 인게임에서는 기본적으로 세 판정이 모두 PURE로만 표시되며, Early/Late PURE는 따로 표시하도록 하는 숙련자용 설정이 있습니다.
- Good = FAR
- Miss = LOST
위키 호스팅 사이트인 Fandom에 있는 Arcaea Wiki 중 Scoring 문서에서 이 게임의 점수 체계를 확인해볼 수 있는데, 이 역시 기준 점수(10,000,000점)를 제외하고 문제에서 제시하는 것과 일치합니다.
- Shiny PURE = 100% + 1점
- 이때 100%는 기준 점수를 노트 수로 나눈 것을 기준으로 합니다.
- Early/Late PURE = 100%
- FAR = 50%
- LOST = 0%
- 콤보는 점수에 전혀 영향이 없습니다. 문제에서도 혼동을 피하기 위해 콤보와 관련된 언급을 일절 하지 않았습니다.
원래는 문제에서도 기준 점수를 10,000,000점으로 두었지만, 범위가 너무 작아서 의도치 않은 풀이를 허용할 수 있다는 검수진의 의견을 수용해 1,000,000,000점으로 늘렸습니다.
마지막으로 같은 문서의 Trivia 문단에는 다음과 같은 언급이 있습니다. 원문에 없는 강조를 추가했습니다.
- 채보2에 충분한 수의 노트가 있을 경우, 이론적으로는 Pure Memory3 없이도 10,000,000점 이상을 획득하는 것이 가능하다.
- 예를 들어, 노트가 2,500개 있는 채보에서 2,499 Shiny PURE + 1 FAR를 받으면 10,000,499점이 된다.
- 최소 \(\lceil 0.5 \times \left( 1 + \sqrt{\left( 2 \times 10,000,000 \right) + 1} \right) \rceil = 2237\)개의 노트가 필요하다. 현재 최대 콤보가 2237 이상인 채보가 없으므로 이는 불가능하다.
이 서술에서 문제의 정해에 대한 힌트를 얻었습니다. 오래 전에 트위터에서 다른 리듬 게임인 Cytus를 소재로 목표 점수를 입력하면 그 점수를 정확히 맞추는 플레이를 출력하는 콘솔 프로그램을 봤던 것도 어느 정도 영향이 있었습니다.
다 쓰고 나서 Arcaea라는 배경지식을 지우니 "그게 뭔데" 싶은 문제가 되어버렸고, 구글 검색이나 solved.ac 난이도 기여에서도 "문제의 의도를 모르겠다"는 반응이 어느 정도 보여서 정말 아쉽습니다. 노트 개수 제한을 20,000이 아니라 22,361로 뒀으면 의도가 더 드러났을까 싶네요.
출제자가 의도한 풀이
먼저 출력 설명의 "가능한 (2a+2b+c, a)의 쌍이 여러 개인 입력은 없다"와 바로 위에서 언급한 "[\(N\)을] 22,361로 뒀으면 의도가 더 드러났을까 싶네요"에 주목해야 하는데, 22,361은 위에서 제시한 2,237과 수상하게 비슷해 보이는 데서 알 수 있듯이 올 퍼펙트를 해야 1,000,000,000점을 달성할 수 있는 최대 노트 수입니다. 이게 풀이랑 무슨 관련이 있냐고요?
문제에서 Good 판정을 일종의 단위로 사용한 것이 또 하나의 힌트가 되는데, 최종 점수 식을 다음과 같이 두 부분으로 분리할 수 있습니다.
- \(10^9 \times \frac{2a + 2b + c}{2N}\) (Good 단위/"큰 단위")
- \(a\) ("작은 단위")
모든 점수를 \(a \; \mathrm{Good} + b\)로 적고 \(a\)를 특정한 값으로 고정했을 때 가능한 점수의 집합을 "띠"라고 합시다. 그러면 주어진 조건 내에서 서로 다른 어떤 띠끼리도 겹치지 않는다는 것을 알 수 있습니다.
더욱 부연 설명을 하자면, 큰 단위의 점수가 \(a\)일 때 (작은 단위의 점수를 받을 수 있는 유일한 판정인) Perfect의 최대 개수는 \(\lfloor \frac{a}{2} \rfloor\)입니다. 여기서 이 띠가 가질 수 있는 작은 단위의 범위가 \(0 \le b \le \lfloor \frac{a}{2} \rfloor\)이 됨을 알 수 있습니다.
그런데 1 Good = \(\frac{10^9}{2N}\)이므로 작은 단위의 범위가 이 값을 넘어가면 띠끼리 겹치는 상황이 생깁니다. 문제의 범위를 대입하면 1 Good = 25,000, \(\lfloor \frac{a}{2} \rfloor \le 10000\)이므로 그런 일은 발생하지 않습니다. 그래서 이게 풀이랑 무슨 관련이 있냐고요?
이제 띠끼리 겹치지 않는다는 사실을 알았으니 점수의 작은 단위를 신경쓰지 않고 큰 단위를 먼저 구할 수 있고, 그 다음에 작은 단위를 구할 수 있습니다. 가능한 큰 단위는 최대 하나뿐이므로 테스트 케이스당 \(O(1)\)에 답을 구할 수 있습니다.
제가 의도한 C11 풀이(정답자만 열람 가능합니다)를 보면 사칙연산만을 사용해 큰 단위와 작은 단위를 하나씩 구하고, 점수가 띠 안에 들어가는지 확인하는 로직 한 번으로 테스트 케이스가 끝나는 것을 볼 수 있습니다.
아무튼 정해가 배배 꼬인 것도, 힌트가 너무 꽁꽁 숨겨져있던 것도 부정할 수는 없을 것 같습니다. 출제를 하면서 #애드 혹을 붙일지 말지 고민했는데, 지금 알고리즘 분류를 봐도 의외로 애드 혹은 없네요.
문제 여담
문제에 나온 것과 같이 실제로 저도 취미로 리듬 게임을 하고(Arcaea 외에도 다양한 게임을 하고, 지금은 A Dance of Fire and Ice와 사운드 볼텍스를 가장 자주 합니다), "정확히 123,456,789점을 획득해 사람들을 놀라게 하고 싶"은 생각도(생각만) 가끔씩 합니다. 당연히 실제 잇창명은 모든 노트의 판정을 원하는 대로 조절할 수 있는 초고수 플레이어가 아닙니다.
CPC 2024
2024 중앙대학교 프로그래밍 경진대회에 세 문제(교내 출제 1문제, 오픈 콘테스트 전용 2문제)를 출제하고, 여섯 문제에 삽화를 제공했습니다.
32175번 "컵 쌓기" (C1번, 교내 출제)
문제
주식회사 푸앙의 추종자인 잇창명은 푸앙에서 생산하는 \(N\)종류의 컵을 가지고 있다. 이 회사에서 생산하는 컵은 쉽게 정리할 수 있도록 종류에 상관없이 컵의 입구 사이에 빈틈이 없도록 포개어진다는 장점이 있다. 편의상, 이 문제에서는 컵의 몸통 부분을 제외한 입구 부분만 생각하기로 하자.
가지고 있는 컵을 포개어 정리하던 잇창명은 문득 컵의 입구 부분의 높이 총합이 \(H\)가 되도록 컵을 포갤 수 있는 경우의 수가 궁금해졌다. 모든 종류의 컵은 무한히 많이 있으며, 각 종류의 컵은 입구의 높이가 정해진 단위 높이 \(1\)의 양의 정수배에 해당한다. 또한, 컵을 포갤 때는 입구가 위로 오도록 포개어야 한다.
아래와 같이 입구의 높이가 각각 \(1\), \(1\), \(2\), \(3\)인 컵 세트를 사용해 구체적인 예시를 들어 보자.
위의 네 종류의 컵을 입구 부분의 높이가 \(10\)이 되도록 쌓는 방법은 아래의 그림 이외에도 여러 가지가 있으며, 그 경우의 수를 모두 합하면 \(9\,003\)가지이다.
잇창명을 위해 컵을 포개는 경우의 수를 구하는 프로그램을 작성해 보자.
입력
첫 번째 줄에 \(N\)과 \(H\)가 주어진다.
두 번째 줄에 \(N\)종류의 컵의 높이 \(A_1\), \(A_2\), \(A_3\), \(\cdots\), \(A_N\)이 공백으로 구분되어 주어진다.
출력
첫 번째 줄에 높이가 정확히 \(H\)가 되도록 컵을 포개는 경우의 수를 \(1\,000\,000\,007\)(\(= 10^9+7\))로 나눈 나머지를 출력한다.
제한
- \(1 \le N \le 100\)
- \(1 \le H \le 100\,000\), \(H\)는 정수
- \(1 \le A_i \le 100\)
- \(1 \le i \le N\)
예제 입력 1
2 3 1 2예제 출력 1
3예제 입력 2
4 10 1 1 2 3예제 출력 2
9003
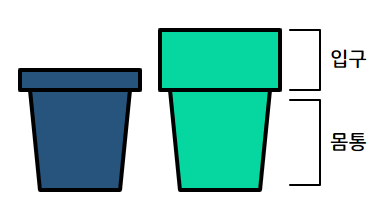

2024년 9월 2일 현재 이 문제의 난이도는 실버 1이며, 알고리즘 분류는 #다이나믹 프로그래밍입니다.
생각해보면 동적 계획법이 정해인 문제 중 점화식이 입력 데이터에 따라 동적으로 바뀌는 문제를 거의 못 본 것 같아서 기획한 문제입니다. 실제로 그런 문제가 많은데 제가 기억을 못 하는 것일 수도 있지만 일단 출제 자체는 기획 의도에 맞게 잘 되긴 했습니다.
0개 이상의 컵을 쌓은 것을 "컵탑"이라고 할 때, 컵탑의 높이 \(H\)에 따라 점화식 \(B_H\)를 다음과 같이 구성할 수 있습니다.
- \(H < 0\): 높이가 음수가 되게 쌓는 것은 당연히 불가능하므로 \(B_H = 0\)가지입니다.
- \(H = 0\): 베이스 케이스에 해당합니다. 컵을 0개 쌓는 \(B_H = 1\)가지 방법이 있습니다.
- \(H > 0\): 기존에 쌓은 컵탑 위에 높이가 \(A_i\)인 \(i\)번 컵을 쌓을 수 있습니다.
- 높이가 \(A_i\)인 컵을 추가로 쌓아서 쌓인 컵탑의 높이를 \(H\)로 만들려면 쌓기 이전에 컵탑의 높이는 \(H - A_i\)여야 합니다. 즉, \(B_{H - A_i}\)가지 방법이 가능합니다.
- 데이터에서 제시된 모든 컵에 대한 경우의 수를 합합니다.
즉, 수식으로 정리하면 다음과 같습니다.
\[B_H = \begin{cases} 0 & H < 0 \\ 1 & H = 0 \\ \Sigma_{i = 1}^N B_{H - A_i} & H > 0 \end{cases}\]정해에서는 \(H < 0\)인 경우를 생략하고 최근 100개 항만 메모리에 유지하고 있습니다(\(A_i \le 100\)이므로).
32180번 "매달린 else" (E1번, 오픈 콘테스트 전용)
문제
아래의
else문은 둘 중 어느if문에 대응하는else문일까?if(a) if(b) c; else d;별도로 규칙을 추가하지 않는다면 컴퓨터는 이
else가 두if중 어느 쪽에 대응하는지 알 수 없다. 이 문제가 컴파일러에 관한 강의에서 들어보았을 매달린 else(dangling else) 문제이다.이 문제를 해결하는 방법은 여러 가지가 있지만, 가장 대표적인 방법은 아래의 두 가지이다.
- 모호한
else를 짝지을 수 있는 가장 가까운if와 짝짓는다.- 문법적으로 중괄호 생략을 금지한다.
이 문제에서는 1번 규칙을 사용하는 소스 코드를 입력받아 2번 규칙을 사용하는 소스 코드로 변환해야 한다.
문제에서 사용할 소스 코드의 문법은 다음과 같다.
- 소스 코드에서 사용하는 토큰은 세미콜론("
;"), 여는 중괄호("{"), 닫는 중괄호("}"), "if", "else", "end"로 총 6가지이다.- 소스 코드는 \(0\)개 이상의 구문과 하나의 "
end" 토큰으로 이루어진다.- 각 구문은 아래의 셋 중 하나에 해당한다.
- 하나의 세미콜론("
;") 토큰- 하나의
if문- 하나의
if-else문if문은 "if" 토큰 하나와 본문 하나가 연이어 있는 형태를 가진다.if-else문은 "if" 토큰 하나, 본문 하나, "else" 토큰 하나, 본문 하나가 연이어 있는 형태를 가진다.- 본문은 위에서 정의한 두 규칙 중 어느 것을 사용하느냐에 따라 다르게 구성될 수 있다.
- 1번 규칙을 사용하는 경우, 본문은 구문 하나로 구성될 수 있다.
- 1번 규칙 또는 2번 규칙을 사용하는 경우, 본문은 여는 중괄호("
{") 토큰 하나, \(0\)개 이상의 구문, 닫는 중괄호("}") 토큰이 연이어 있는 형태를 가질 수 있다.- 모든 토큰은 공백 문자 \(1\)개를 사이에 두고 구분한다.
또한, 문법 요소 간의 동형 관계는 다음과 같이 주어진다.
- 두 소스 코드는 구문 수가 같고 각 구문끼리 순서대로 대응시켰을 때 동형일 경우 동형이다.
- 두 구문은 다음 중 하나에 해당하면 동형이다.
- 두 구문이 모두 단일 세미콜론("
;") 토큰일 경우- 두 구문이 모두
if문이며 서로 동형일 경우- 두 구문이 모두
if-else문이며 서로 동형일 경우- 두
if문은 그 본문끼리 동형일 경우 동형이다.- 두
if-else문은 두 본문을 순서대로 대응시켰을 때 동형일 경우 동형이다.- 두 본문은 다음 중 하나에 해당하면 동형이다.
- 두 본문이 모두 중괄호가 있으며, 구문 수가 같고 각 구문끼리 순서대로 대응시켰을 때 동형일 경우
- 두 본문이 모두 중괄호의 유무와 상관 없이 단일 구문이며, 구문이 서로 동형일 경우
예를 들어, 1번 규칙을 고려하지 않는다면 소스 코드
if { if ; } else ; end와 소스 코드if if { ; } else { ; } end는 동형이며, 그 이유를 다음과 같이 보일 수 있다.
- 두 소스 코드 모두 단일 구문(
if { if ; } else ;와if if { ; } else { ; })으로 이루어져 있으며, 두 구문 모두if-else문에 해당한다.
- 첫 번째 본문(
{ if ; }와if { ; })이 모두 단일 구문으로 이루어져 있다.
- 두 구문 모두
if문에 해당하며, 본문(;와{ ; })이 서로 일치하는 단일 구문으로 이루어져 있다.- 두 번째 본문(
;와{ ; })이 서로 일치하는 단일 구문으로 이루어져 있다.여러분에게 1번 규칙을 사용하는 소스 코드 \(X\)가 주어진다. 여러분은 이 소스 코드와 동형이면서 2번 규칙을 사용하는 소스 코드 \(X'\)를 찾아 출력해야 한다. 문제에서 주어진 소스 코드의 문법을 따를 때 그러한 소스 코드 \(X'\)는 유일함을 증명할 수 있다.
입력
첫 번째 줄에 문제에서 제시된 입력 문법을 만족하는 문자열이 주어진다. 토큰의 개수는 "
end"를 포함해서 최대 \(1\,000\)개이며, 입력의 앞뒤에 불필요한 공백이 주어지지 않는다.형식적인 입력 문법은 아래와 같다. 이때
<input_stmt>*는<input_stmt>가 \(0\)개 이상 올 수 있다는 의미이다.<input> ::= <input_stmt>* "end" <input_block> ::= <input_stmt> | "{" <input_stmt>* "}" <input_stmt> ::= ";" | <input_if> <input_if> ::= "if" <input_block> | "if" <input_block> "else" <input_block>출력
첫 번째 줄에 입력받은 프로그램을 파싱한 결과를 문제에서 제시된 출력 문법을 만족하도록 출력한다.
형식적인 출력 문법은 아래와 같다. 이는 위의
<input_block>에서<input_stmt>만 제거한 것과 동일하다.<output> ::= <output_stmt>* "end" <output_block> ::= "{" <output_stmt>* "}" <output_stmt> ::= ";" | <output_if> <output_if> ::= "if" <output_block> | "if" <output_block> "else" <output_block>예제 입력 1
if if ; else ; end예제 출력 1
if { if { ; } else { ; } } end예제 입력 2
if { if ; } else ; end예제 출력 2
if { if { ; } } else { ; } end예제 입력 3
if { if ; else ; ; ; } end예제 출력 3
if { if { ; } else { ; } ; ; } end예제 입력 4
if if if if if if ; end예제 출력 4
if { if { if { if { if { if { ; } } } } } } end예제 입력 5
end예제 출력 5
end예제 입력 6
; ; ; ; ; ; ; ; end예제 출력 6
; ; ; ; ; ; ; ; end예제 입력 7
; if ; else { } if { ; } if { } else ; ; end예제 출력 7
; if { ; } else { } if { ; } if { } else { ; } ; end노트
사실 C에는
else if문이 따로 없다는 사실을 알고 있는가? 우리가else if라고 알고 있는 구문은 사실 일반적인else의 본문에서 중괄호를 생략하고if문으로 채운 경우에 해당한다.
2024년 9월 2일 현재 이 문제의 난이도는 플래티넘 5이며, 알고리즘 분류는 #자료 구조 #문자열 #파싱 #스택 #재귀입니다.
이 문제만큼 난이도 예측에 실패한 적이 없을 것 같습니다. 4949번 "균형잡힌 세상"이나 2504번 "괄호의 값" 등의 단순 심화 버전으로 기획하고 실버 중상위권 정도의 난이도를 예상했는데, 막상 뚜껑을 열어보니 플래티넘 턱걸이를 하는 문제가 나왔습니다. 추가로 문제 자체가 검수하기 어려운 형태이고 지문도 엄밀하게 작성해야 하다 보니 "다시는 이런 문제 내지 말아야지" 하는 다짐을 유발하기도 했습니다.
위의 괄호 문자열 문제에서 현재 읽고 있는 위치(|)를 다음과 같이 열거형으로 표현할 수 있었듯이...
- 소괄호 안 (
( ... | ... )) - 대괄호 안 (
[ ... | ... ])
이 문제에서도 다음과 같은 열거형을 정의해 스택으로 관리할 수 있습니다. 설명의 편의상 이름을 붙이겠습니다.
S_IF:if문/if-else문의 첫 번째 본문 이전 (if | ...혹은if | ... else ...)S_THEN:if문/if-else문의 첫 번째 본문 이후 (if ... |혹은if ... | else ...)S_ELSE:if-else의 두 번째 본문 이전 (if ... else | ...)S_BLOCK: 중괄호 안 ({ ... | ... })
그런 다음에는 토큰을 읽을 때마다 다음과 같이 스택 갱신과 출력을 병행하면 됩니다. "스택의 가장 위에 토큰 X가 있을 때"는 글 작성의 편의상 "X 상태일 때"로 축약합니다.
- 공통 사항
S_IF나S_ELSE상태(본문이 올 자리)일 경우 다음 토큰으로는 본문을 구성할 수 있는 토큰만 올 수 있습니다.S_THEN상태에서else토큰이 오지 않을 경우에는if-else문이 아니므로S_THEN을 정리해야 합니다(if문 정리).- 처리해야 할
S_THEN이 여러 겹 있을 수 있음에 유의해야 합니다.
- 처리해야 할
- 본문이 열릴 때와 닫힐 때는 특수한 처리(본문 여닫기)가 필요합니다. 특히 중괄호가 생략됐는지 판단하여 추가로 출력하고, 본문이 닫힐 때
S_IF는S_THEN으로 갱신,S_ELSE는 뽑아야 합니다.if문 정리 도중에도 본문 닫기 판정이 생길 수 있음에 유의해야 합니다.
- 세미콜론(
;)- 본문이 올 자리일 경우 본문 여닫기를 합니다.
- 그렇지 않으면 세미콜론이 일반 구문이므로
if문을 정리합니다.
- 여는 중괄호(
{)- 이 토큰은 본문의 첫 토큰으로만 등장할 수 있습니다. 본문 열기를 하고 스택에
S_BLOCK을 넣습니다.
- 이 토큰은 본문의 첫 토큰으로만 등장할 수 있습니다. 본문 열기를 하고 스택에
- 닫는 중괄호(
})- 이 토큰은 본문의 마지막 토큰으로만 등장할 수 있습니다.
if문을 정리하고 스택의S_BLOCK을 꺼낸 뒤 본문 닫기를 합니다.
- 이 토큰은 본문의 마지막 토큰으로만 등장할 수 있습니다.
if- 본문이 올 자리일 경우 본문 열기를 한 뒤 스택에
S_IF를 넣습니다. - 그렇지 않으면
if(-else)문이 일반 구문이므로if문을 정리하고 스택에S_IF를 넣습니다.
- 본문이 올 자리일 경우 본문 열기를 한 뒤 스택에
else- 이 토큰은 본문의 바로 다음에만 등장할 수 있습니다. 스택의
S_THEN을S_ELSE로 갱신합니다.
- 이 토큰은 본문의 바로 다음에만 등장할 수 있습니다. 스택의
end- 입력의 종료를 나타내는 토큰입니다.
if문을 정리합니다.
- 입력의 종료를 나타내는 토큰입니다.
여기까지가 제가 의도한 대회 중에 작성할 수 있는 풀이였고, 모종의 방법을 이용하면 문제에서 제시하는 언어(문법이 아닙니다!)4를 LR 파싱할 수 있으니 관심이 있다면 도전해보시는 것도 좋겠습니다. 실제로 데이터 검증 코드가 이렇게 구현되어 있습니다.
문제 여담
사실 C에서는 0이 8진수라는 것도 알고 계셨나요? C17 표준의 최종안인 ISO C N2176에서는 정수 상수의 문법이 다음과 같이 정의되어 있습니다. opt는 바로 앞의 문법 요소가 있어도 되고, 없어도 된다는 의미입니다.
- integer-constant:
- decimal-constant integer-suffixopt
- octal-constant integer-suffixopt
- hexadecimal-constant integer-suffixopt
- decimal-constant:
- nonzero-digit
- decimal-constant digit
- octal-constant:
0- octal-constant octal-digit
- ...
- nonzero-digit: one of
123456789
10진 상수(decimal-constant)는 0으로 시작할 수 없고(nonzero-digit), 0으로 시작하는 것은 모두 8진 상수(octal-constant)인 것으로 정의되어 있습니다. 0도 예외는 아닙니다.
32183번 "바이러스" (F1번, 오픈 콘테스트 전용)
문제
신종 컴퓨터 바이러스가 전 세계를 휩쓸고 있다! 바이러스를 분석하고 치료하는 데 당신의 도움이 필요하다.
현재 가용한 정보를 취합해서 얻어낸 바이러스의 비트 패턴은 정규 표현식으로 다음과 같다.
(1(10)+1*|0+10)+정규 표현식은 문자열에 여러 가지 연산을 추가해 원하는 패턴을 기술할 수 있게 한 것으로, 다음과 같이 읽으면 된다.
- 비트를 그대로 적으면 정확히 일치하는 한 글자의 비트열을 찾는다.
0= {"0"}1= {"1"}- 모든 정규 표현식
x와y에 대해 다음 연산이 성립한다.
- 괄호를 씌운
(x)는x와 일치하는 비트열을 동일하게 찾는다.
(0)= {"0"}(1)= {"1"}- 연산자 없이 두 정규 표현식을 연결한
xy는 두 정규 표현식과 일치하는 비트열 중 하나씩을 순서대로 연결한 비트열을 찾는다.
000= {"000"}10010110= {"10010110"}x|y는x와 일치하는 비트열과y와 일치하는 비트열 중 아무 비트열을 찾는다.
0|1= {"0","1"}0(0|1)1= {"001","011"}1|111|11111= {"1","111","11111"}x*는x와 일치하는 비트열이 \(0\)개 이상 연결되어 있는 비트열을 찾는다. 즉,x*는(빈 문자열)|x|xx|xxx|...와 같은 의미를 가진다.
0*= {"","0","00","000", … }01*= {"0","01","011","0111", … }(01)*= {"","01","0101","010101", … }111(01|001)*= {"111","11101","111001","1110101","11100100101","1110100100101", … }x+는x와 일치하는 비트열이 \(1\)개 이상 연결되어 있는 비트열을 찾는다. 즉,x+는x|xx|xxx|...와 같은 의미를 가진다.
0+= {"0","00","000", … }01+= {"01","011","0111", … }(01)+= {"01","0101","010101", … }(01+)+= {"01","011","01111","0111010101","01111011111011", … }연산자를 적용하는 순서는 다음과 같다. 예를 들어,
01|10**는(01)|(1((0*)*))와 같이 읽는다.
(x)x*,x+
- 두 연산자의 우선순위는 같다.
xyx|y특히 이 바이러스는 자신의 비트열을 계속 바꾸면서 예측할 수 없는 움직임을 보이기 때문에 비트열이 바뀔 때마다 빠른 연산과 탐지를 필요로 한다. 구체적으로 비트열이 다음과 같이 갱신될 수 있다.
- \(fg\;l\;r\): \(l\)번째 비트부터 \(r\)번째 비트까지가 다음과 같이 갱신된다. 비트 번호는 왼쪽에서 오른쪽으로 \(0\)부터 세며, \(l\)과 \(r\)이 모두 포함된다.
- 갱신 이전에
0이었던 비트는 \(f\)로 바뀐다.- 갱신 이전에
1이었던 비트는 \(g\)로 바뀐다.미리 탐지한 메모리 구역에 해당하는 비트열이 주어지면, 해당 비트열이 갱신될 때마다 바이러스의 비트 패턴과 일치하는지 확인하는 프로그램을 작성하라.
입력
첫 번째 줄에 메모리 구역의 비트 수 \(N\)이 주어진다.
두 번째 줄에 해당 메모리 구역의 초기 데이터 \(S\)가 숫자
0과1만으로 이루어진 문자열로 주어진다.세 번째 줄에는 데이터가 갱신되는 횟수 \(Q\)가 주어진다.
네 번째 줄부터 \(Q\)개의 줄에 걸쳐 데이터 갱신 정보가 한 줄에 하나씩, \(fg\;l\;r\) 형태로 주어진다. \(f\)와 \(g\) 사이에 공백 문자가 오지 않음에 유의하라.
출력
첫 번째 줄에 초기 비트열이 바이러스의 비트 패턴과 일치하면
YES를, 그렇지 않으면NO를 출력한다.두 번째 줄부터 비트열이 갱신될 때마다 갱신된 비트열이 바이러스의 비트 패턴과 일치하면
YES를, 그렇지 않으면NO를 각각 한 줄로 출력한다.출력하는 모든 문자는 대문자이며, 따옴표는 출력하지 않는다.
제한
- \(1 \le N, Q \le 100\,000\)
- \(\vert S \vert = N\)
- 모든 갱신은 \(f, g \in { 0, 1 }\)과 \(0 \le l \le r \le N - 1\)을 만족한다.
예제 입력 1
10 0010110101 4 10 0 4 10 7 9 11 0 5 00 4 9예제 출력 1
YES YES YES NO NO주어진 메모리 구역의 비트열은 다음과 같이 갱신되었다.
0010110101(초기 데이터)1101010101(1차 갱신,10 0 4)1101010010(2차 갱신,10 7 9)1111110010(3차 갱신,11 0 5)1111000000(4차 갱신,00 4 9)
2024년 9월 2일 현재 문제에 기여를 남긴 사람이 저와 내부 검수자 한 명밖에 없어서 문제 난이도나 알고리즘은 적지 않습니다. 출제 시에는 난이도를 다이아몬드 하위권으로 예상했습니다.
이 문제를 구상하는 데 여러 문제의 영향을 받았습니다.
- 원래 1013번 "Contact"/2671번 "잠수함식별"의 쿼리 버전으로 기획했던 문제였습니다. 모 조직의 커뮤니티 문제 표절 이슈가 문제 출제 시기와 맞물려 현재의 지문과 정규 표현식으로 변경했습니다.
- 17407번 "괄호 문자열과 쿼리"와 22854번 "고장난 계산기 (Calculator) 게임"의 영향을 받았으며, 특히 이 문제를 후자의 쉬운/접근성 있는 버전으로 포지셔닝하려는 의도도 어느 정도 있었습니다.
이 문제를 해결하는 데는 여러 단계의 발상이 필요합니다.
정규 표현식을 DFA로 변환
이 문제를 해결하려면 정규 표현식을 DFA로 변환하는 일련의 흐름을 사전 지식으로 알고 있어야 합니다. 간단한 요약을 같이 작성합니다.
- (형식언어론 맥락에서의) 정규 표현식
- 문제에서 정규 표현식의 문법 일부를 설명했는데, 정규 표현식으로 기술할 수 있는 언어를 따로 정규 언어라고 합니다. 문제에는 없지만 상황에 따라 정규 언어의 표현력 이내에서 다음 연산자나 문법을 추가로 도입하기도 합니다.
- 아무 문자열도 찾지 않는 공집합 정규 표현식. 관례상
∅으로 적습니다. - 빈 문자열
""을 찾는 정규 표현식. 관례상ε으로 적습니다. - 0개 혹은 1개를 찾는 연산자
x?.ε|x와 같은 의미를 가집니다. - 집합에 속하는 한 문자를 찾는 문법
[...]. 예를 들어[abc]는a|b|c와 같은 의미를 가집니다. - 집합에 속하지 않는 한 문자를 찾는 문법
[^...]
- 아무 문자열도 찾지 않는 공집합 정규 표현식. 관례상
- 참고로 관례상
x*는 "클레이니 스타",x+는 "클레이니 플러스"라고 읽습니다.
- 문제에서 정규 표현식의 문법 일부를 설명했는데, 정규 표현식으로 기술할 수 있는 언어를 따로 정규 언어라고 합니다. 문제에는 없지만 상황에 따라 정규 언어의 표현력 이내에서 다음 연산자나 문법을 추가로 도입하기도 합니다.
- Thompson's construction
- 정규 표현식을 아래에서 설명할 NFA로 변환하는 알고리즘입니다.
- 비결정론적 유한 상태 기계 (Nondeterministic Finite Automaton; NFA)
- 유한개의 상태를 가지는 기계로, 다음 규칙에 따라 문자열을 인식합니다.
- 기계에는 하나의 시작 상태와 한 개 이상의 "목표 상태"(accepting state)가 있습니다.
- 각 상태마다 특정한 문자열을 입력받았을 때 전이할 수 있는 다음 상태가 정해져 있습니다.
- 예를 들어 1번 상태에서
0을 입력받으면 2번 혹은 3번 상태,1을 입력받으면 2번 혹은 4번 상태로 전이할 수 있습니다. - 각 상태-문자열 쌍마다 전이할 수 있는 상태의 수에는 제한이 없으며, 0개 역시 가능합니다.
- 예를 들어 1번 상태에서
- 추가로 전이할 때만 빈 문자열
ε역시 문자로 인정하기도 하며, 이 경우 기계가 작동하는 중 아무 때나ε전이를 하거나, 하지 않을 수 있습니다.ε전이가 있는 NFA를 따로 ε-NFA로 부르기도 하는데, 이 글에서는 구분 없이 모두 NFA로 지칭합니다.
- 문자열의 모든 문자를 순서대로 입력하면서 보드게임을 하듯이 상태를 전이시킵니다.
- 그 결과 상태 전이가 없는 상태에 갇히지 않고 "목표 상태"에 멈추는 방법이 하나라도 존재한다면 기계는 이 문자열을 인식(accept)합니다.
- "목표 상태"에 멈추는 방법이 하나도 없다면 기계는 이 문자열을 거부(reject)합니다.
- 유한개의 상태를 가지는 기계로, 다음 규칙에 따라 문자열을 인식합니다.
- Powerset construction
- NFA를 아래에서 설명할 DFA로 변환하는 알고리즘입니다.
- 결정론적 유한 상태 기계 (Deterministic Finite Automaton; DFA)
- NFA와 비슷하지만 각 상태-문자열 쌍마다 최대 하나의 상태로만 전이할 수 있으며,
ε전이 역시 금지됩니다. - NFA와 다르게 여러 가지 경로를 추적하지 않아도 되므로("결정론적"이므로) 컴퓨터로 효율적인 구현이 가능합니다.
- NFA와 비슷하지만 각 상태-문자열 쌍마다 최대 하나의 상태로만 전이할 수 있으며,
- DFA 최소화
- DFA에서 시작 상태에서 도달할 수 없는 상태, 목표 상태에 도달할 수 없는 상태, 서로 구별할 수 없는 상태를 제거해 상태의 수를 최소화하는 기법입니다.
위의 모든 과정을 손으로 계산해야 하는 것은 아니고, 웹상의 도구를 이용할 수 있습니다. 저는 CyberZHG님의 정규 표현식 → 최소 DFA 변환 도구를 이용했습니다.
문제에서 제시한 정규 표현식인 (1(10)+1*|0+10)+을 최소 DFA로 변환한 결과는 다음과 같습니다. 시작 상태는 0이며, 모든 상태 번호에서 1을 빼는 가공을 거쳤습니다.
| 상태 번호 | 0 | 1 | Accept? |
|---|---|---|---|
| 0 | 2 | 3 | |
| 1 | 2 | 7 | ✅ |
| 2 | 2 | 4 | |
| 3 | 5 | ||
| 4 | 6 | ||
| 5 | 1 | ||
| 6 | 2 | 3 | ✅ |
| 7 | 1 | 7 | ✅ |
2번째·3번째 세로줄의 빈칸은 상태 전이가 없어서 DFA가 문자열을 거부하는 경우이며, 코드로 구현할 때는 -1을 대신 사용할 수 있습니다.
상태 전이를 세그먼트 트리로 관리
함수는 정의역의 모든 원소를 공역의 원소와 대응시킨 것인데, 위 상태 전이 함수의 경우에는 정의역의 원소가 8개뿐이므로 배열로 전부 기록할 수 있습니다. 예를 들어 비트열 0에 해당하는 상태 전이 배열은 C/C++ 문법으로 { 2, 2, 2, -1, 6, 1, 2, 1 }입니다. 추가로 길이가 2 이상인 비트열의 상태 전이 배열 역시 비트열을 이루는 비트를 상태 전이 배열로 변환하고 함수 합성을 해서 구할 수 있습니다.
이제 상태 전이 배열에 결합법칙이 성립하는 이항 연산이 있으니 문자열 전체의 상태 전이 배열을 세그먼트 트리로 관리할 수 있습니다. 문자열 인식은 문자열의 상태 전이 배열을 구하고 0에서의 함숫값, 즉 0번째 원소를 구한 뒤 그 상태가 "목표 상태"인지 확인하면 됩니다.
갱신 결과를 세그먼트 트리에 같이 저장
구간 갱신까지 처리하려면 추가로 한 가지 발상이 더 필요합니다. 이 문제에서는 함수 합성을 고려하더라도 가능한 갱신이 00, 01, 10, 11의 네 종류뿐인데, 상태 전이 함수의 모든 함숫값을 같이 저장했으니 가능한 모든 갱신 결과도 같이 저장하지 못할 이유가 없다는 것입니다.
예를 들어, 비트 0을 세그먼트 트리로 관리하려면 기존의 ("0"의 상태 전이 배열)이 아닌 { ("0"의 상태 전이 배열), ("0"의 상태 전이 배열), ("1"의 상태 전이 배열), ("1"의 상태 전이 배열) }을 저장한 뒤, 구간 갱신을 다음과 같이 처리하면 됩니다.
00질의:{ a, b, c, d }를{ a, a, d, d }로 갱신01질의:{ a, b, c, d }를{ a, b, c, d }로 갱신10질의:{ a, b, c, d }를{ a, c, b, d }로 갱신11질의:{ a, b, c, d }를{ a, d, a, d }로 갱신
문자열 인식은 01 질의에 해당하는 b를 꺼내어 위와 같이 확인하면 됩니다.
대회 여담

트위터 신세대 의문(@NewGenHmmm)님의 밈 이미지를 편집한 이미지입니다.
여담
물론 문제 출제에서도 보람을 느끼고 있지만, 삽화 작업에서도 꽤 보람을 느끼는 편입니다(일단 삽화는 눈에 바로 보이는 편이니까).
위에 언급된 대회의 삽화 중에 뭔가 은근히 귀엽고 나눔스퀘어라운드(이 블로그의 제목체입니다)가 보이면 제 작업물이라고 생각해 주세요. 특히 CHAC 2022와 CPC 2024의 모든 삽화는 제가 그렸습니다. 😜
사실은 이번 대회 준비하면서 공을 많이 들인 3짤4짤을 보여드리고 싶었는데요 https://t.co/E9GV0GsWeQ pic.twitter.com/SUNUOX6BR9
— 잇창명 EatChangmyeong💕 (@EatChangmyeong) August 31, 2024
-
직역하면 "맞았습니다!!에 의한 증명". 알고리즘의 엄밀한 증명이 필요한 프로그래밍 문제에서, 엄밀한 증명 없이 제출해 AC(Accepted; 백준 온라인 저지의 맞았습니다!!에 해당하는 채점 결과)를 받은 것을 "증명"으로 취급하는 농담. ↩
-
Chart. 특정한 악곡의 특정한 난이도에서 등장하는 노트의 배열. ↩
-
특정한 채보에서 모든 노트를 Shiny 여부와 상관 없이 PURE로 처리하면 받는 칭호 ↩
-
문법은 언어를 기술하는 규칙이고, 언어는 (그 언어에) 포함되는 문자열의 집합이므로 둘은 다른 의미를 가지며, 구분되어야 합니다. 문제에서 제시하는 문법은 그 자체로는 모호하지만, 같은 언어를 기술하면서도 모호하지 않은 문법을 제시할 수 있습니다. ↩