현재 블로그 이전 작업 중입니다. 새 블로그에서 글을 읽어보실 수 있습니다.
이 글은 단축링크 https://eatch.dev/s/ctype으로도 들어올 수 있습니다.
C 코딩을 할 때, 다음 중 가장 "올바른" 코딩 스타일은 무엇일까요?
int*x;int* x;int *x;int * x;
물론 정답은 없습니다. 코딩 스타일이 원래 스페이스냐 탭이냐로 싸우는 주제잖아요. 스페이스 3칸 너비의 탭(???)이나 int * x;처럼 누가 봐도 오답인 것이 있긴 합니다.
저라면 이 질문에 무조건 int *x;라고 답할 것입니다. 물론 근거 없이 int *x;라고 우기는 것은 아닙니다. 그동안 C 타입 시스템에 관심이 있어서 cppreference 문서를 이것저것 읽어봤는데, 읽으면 읽을수록 int* x;가 아니라 int *x;가 맞다는 확신이 들더라고요. 추가로 그동안 될 거라고 생각조차 못 했던 문법도 여러 가지 알게 되었습니다.
네. 이 글은 C 타입 시스템에 대해 정리하는 글입니다. C의 타입 시스템을 여러 부분으로 나누어 하나씩 있는 그대로 설명하고, 주의할 점이 있으면 같이 적으려고 합니다.
위에서 언급한 int *x; 이외에도 C 타입 시스템을 더 잘 이해한다면...
int *(*(*x)(char *))[64];같은 헷갈리는 선언을 그나마 쉽게 읽을 수 있습니다.- 근데 웬만하면 이런 식으로 선언하지 말아주세요.
- 배열과 포인터가 정확히 어떻게 다른지를 이해할 수 있습니다.
- 단 한 번의
malloc호출로 다차원 배열을 동적 할당받을 수 있습니다. typedef가 조금 더 직관적으로 다가올 수도 있습니다.const int *x와int const *x와int * const x의 차이를 이해할 수 있습니다.
오호! 3번은 금시초문, 나머지는 헷갈리는 것들이군요. 여기서 뿌린 떡밥은 글이 끝나기 전까지 전부 회수할 예정이니 걱정 말아주세요. 이 글을 읽으면서 C 타입 시스템은 왜 그렇게 복잡한지 조금이라도 이해할 수 있게 된다면 좋겠습니다.
본격적으로 시작하기 전에 참고해주셨으면 하는 점이 있다면...
- 업데이트할 것이나 빠진 것이 생기면 제가 그때그때 찾아와서 업데이트할 예정입니다. 글의 맨 위에 수정한 날짜가 있으니 자주 찾아와서 바뀐 것이 있는지 확인해 보세요.
- C가 어느 정도 익숙해졌을 때 읽어보는 것을 권장드립니다.
- C 타입 시스템에서 제가 설명할 수 있을 정도로 이해한 모든 부분을 얕게 설명합니다. 세부사항은 검색해서 확인해 주세요. cppreference.com 자료를 권장드립니다.
- 타입별 크기와 정렬,
_Alignas(C11~),_Atomic(C11~), 타입 호환성은 제가 충분히 이해하지 못했다고 생각해 부득이하게 제외합니다. - 제가 맘대로 번역한 단어가 섞여있을 수 있으니 구글링을 할 때는 가급적 영문으로 검색해 주세요. 괜찮은/통용되는 번역어가 있다면 제보해 주세요.
- 타입별 크기와 정렬,
- 글이 꽤 길고 건조하기 때문에 원하는 순서와 속도로 읽으셔도 괜찮지만, 제가 문단 순서를 읽기 쉽도록 배치했기 때문에 순서대로 읽는 걸 권장드립니다.
- 모든 내용을 이해할 필요는 없습니다. 평소대로 코딩하다가 타입 시스템 때문에 이상하게 막힐 때나 궁금해졌을 때 찾아와서 읽어주세요.
피드백은 글 맨 아래에 있는 댓글창으로 부탁드립니다.
C 표준 확인하고 가세요
본격적으로 시작하기 전에 잠깐 삼천포로 빠지겠습니다. C 표준은 그동안 여러 번의 개정을 거쳤습니다.
C 표준이 있기 전에는 The C Programming Language(hello, world를 대중화시킨 그 책이 맞습니다)가 사실상의 표준 역할을 했습니다. 이 시절의 C "표준"을 저자 이름의 앞글자를 따서 K&R C라고 합니다. 이후 1989년에 최초로 C89라는 표준이 생겼고, 이후 C95, C99, C11, C17, C23까지 5번의 개정을 거쳤습니다. C17은 기능 추가 없이 결함만 수정했습니다.
이런 내용을 알아야 하는 이유는... 개정판에 따라 쓸 수 있는 문법과 없는 문법이 나뉘기 때문입니다. 예를 들어서 C99 이전까지는 for문 안에 선언을 할 수 없었습니다.
for(int i = 0; i < 8; i++) // 'for' loop initial declarations are only allowed in C99 or C11 mode
printf("%d\n", i);
이 글에서 표준을 인용할 경우 C23 표준 최종안에서 인용한 것임을 밝힙니다. 실제 C23 표준은 ISO에서 유료로 판매하고 있으며, 이전 개정판은 ANSI에서 구매하거나 최종안을 열람할 수 있습니다.
이 글에서는 필요할 때마다 표준 개정판 표기를 넣을 예정입니다. 예를 들어 (C11~)은 C11에 추가된 기능이라는 의미이고, (👎 C23~)은 C23부터 비권장(deprecated)으로 전환된 기능이라는 의미입니다. 표준 문제로 컴파일이 안 된다면 컴파일러에 다음과 같이 플래그를 넣어주세요.
- C89:
-ansi혹은-std=c90 - C95:
-std=iso9899:199409 - C99:
-std=c99 - C11:
-std=c111 - C17:
-std=c17 - C23: 컴파일러 버전에 따라
-std=c2x혹은-std=c23(개발 중에는 C2x라는 가칭을 사용했습니다. 공표된 지 얼마 되지 않은 개정판이므로 컴파일러 버전에 따라 동작이 바뀌거나 불안정할 수 있습니다)
컴파일러를 직접 다루지 않는 IDE 환경이라도 보통 설정에서 컴파일러 플래그나 표준 개정판을 바꿀 수 있으며, 제가 모든 IDE를 써본 게 아니기 때문에 자세한 방법은 구글링을 해 보세요. 아니면 IDE 자체를 업데이트하는 것도 방법입니다2.
선언문
사실 C의 타입 시스템은 선언문과 떼려야 뗄 수 없는 관계입니다. C 프로그래밍을 하면서 타입을 적어넣는 곳이라고 하면 십중팔구 선언문이니 그럴 수밖에 없죠. 그런 의미로 선언문부터 시작해 봅시다.
기본적인 선언문의 구조는 다음과 같습니다(초기화 구문은 생각하지 않습니다).
BaseType declarator;
BaseType과 declarator의 두 부분으로 나뉘는데, 간단히 말해 BaseType은 선언할 것의 기본 타입, declarator는 선언할 것의 이름을 나타냅니다. declarator는 0개 이상을 콤마로 구분해서 작성할 수 있는데, 구조체 선언이 아닌 이상 진짜로 0개를 선언하면 의미가 없죠.
declarator는 선언할 식별자3 이외에도 *나 [] 등을 포함합니다. 즉, int *x;라고 썼다면 BaseType은 int, declarator는 *x입니다. 이제 int *x;가 맞는 이유가 확실해졌습니다.
잠시만요, 그래도 너무 성급한 거 아닌가요? *가 왜 declarator로 들어가는데요? 당연히 이것도 근거가 없는 게 아닙니다. 다음 코드를 생각해 봅시다.
int* x, y;
누구나 한 번쯤 "이렇게 쓰면 x랑 y 모두 포인터겠지??"라고 생각하다가 x만 포인터인 걸 깨닫고 놀랐던 경험이 있을 겁니다. 이런 의외의 동작은 언어 단계에서
int(BaseType)*x(declarator)y(이것도declarator)
로 묶은 결과인데, 이 동작을 납득한다면 *가 declarator로 들어가는 것에는 더 의문이 없을 것 같습니다. 하지만 declarator에는 더 깊은 의미가 있는데...
declarator에 숨은 철학
declarator는 BaseType을 얻기 위해 거치는 연산을 나타냅니다.
아무 IDE(정 어렵다면 ideone이나 Compiler Explorer)를 붙잡고 따라해 보세요. printf 같은 함수에 넣으면 컴파일러가 타입 체킹을 해주니 확인하는 건 어렵지 않을 겁니다.
int x;에서x는int입니다.- 여기에 올바른 타입의 변수를 선언하는 예제 코드가 들어갑니다.
int x;는 자명하니 생략합니다.
- 여기에 올바른 타입의 변수를 선언하는 예제 코드가 들어갑니다.
int *x;에서*x는int입니다.-
int w = 5, *x = &w;
-
int x[64];에서x[18]은int입니다.-
int x[64]; x[18] = 123;
-
int *x[123];에서*x[0]은int입니다.-
int w = 5, *x[123]; x[0] = &w;
-
int (*x)[8];에서(*x)[2]는int입니다.-
int w[8] = { 1, 2, 3, 4 }, (*x)[8] = &w;
-
int (*(*x[3])[4])[5]에서(*(*x[0])[0])[0]은int입니다.-
int a[5] = { 9 }, (*b)[5] = &a, (*c[4])[5] = { b }, (*(*d)[4])[5] = &c, (*(*x[3])[4])[5] = { d };
-
과연 우연일까요? 딱히 그래보이지는 않네요. 사전 지식 없이 C 타입 시스템을 처음 접하면 헷갈리게 보이는 이유가 바로 이것이었습니다. 이 내용은 cppreference.com에서도 언급하고 있습니다.
이 얘기는 파생 타입 얘기할 때 마저 하겠습니다.
선언문 해부하기
선언문은 이 글에서 언급할 거의 모든 개념을 함축하고 있습니다. 생각보다 많은 것들이 단 하나의 선언문 문법을 따릅니다.
BaseType에는 다음과 같은 것들이 올 수 있으며, 무엇이 들어가느냐에 따라 그 선언의 성질을 바꿀 수 있습니다.
- 타입 지정자 (선언할 것의 기본적인 타입 정보)
- 1개 이하의 기억 영역 분류 지정자
- 0개 이상의 한정자
- 0개 이상의 함수 지정자4
- 0개 이상의
_Alignas
여기 오는 모든 것은 단어 단위로 순서와 상관 없기 때문에 아래에 주어지는 쌍은 모두 같은 타입을 가리킵니다.
signed char와char signedint long signed long과long long(signed와int는 생략 가능하므로)_Complex long volatile static double과static long double _Complex volatile
가독성을 위해 웬만하면 하지 말아주세요.
declarator는 다음 중 하나를 만족하는 것입니다. 실제로는 조금 더 복잡한데, 글을 쓰면서 하나하나 짚어볼 예정입니다.
- 식별자 (정의되는 변수, 함수, 타입 등의 이름)
- 기존의
declarator에...
낮선 단어를 마구 써내려가면서 설명을 안 했으니 전혀 이해가 안 돼도 잘못된 건 아닙니다. 이제부터는 여기에 나온 개념들을 하나하나 짚어보겠습니다.
타입 지정자
이 글에서는 타입을 크게 기본 타입, 파생 타입, 복합 타입으로 나누며, 이중 파생 타입과 복합 타입은 다른 글에서와 조금 다른 의미로 사용합니다.
- 포인터, 배열, 함수는 파생 타입입니다.
- 구조체, 공용체, 열거형은 복합 타입입니다.
- 열거형은 구조체와 공용체와는 성질이 다르지만, 선언 문법이 비슷하고 여러 개의 원소를 동시에 선언하기 때문에 복합 타입으로 분류했습니다.
원래는 포인터, 배열, 함수, 구조체, 공용체, _Atomic을 모두 파생 타입이라고 합니다.
typeof(x)와 typeof_unqual(x) 연산자(C23~)도 타입 지정자로 사용할 수 있으며, 괄호 안에 들어간 표현식의 타입을 그대로 작성한 것과 같은 효과를 가집니다. typeof_unqual(x)은 typeof(x)에서 _Atomic과 한정자가 제거된 타입과 같습니다.
기본 타입
C에 정의된 (라이브러리 지원이나 매크로를 제외하고) 기본 타입에는 다음과 같은 것들이 있습니다. C 표준에서는 대분류를 다르게 하긴 하지만 여기서는 키워드끼리 조합할 때 가장 간단하게 되도록 묶었습니다.
void- 불린 (C99~):
_Bool#include <stdbool.h>를 하면_Bool을bool로 쓸 수 있습니다.
- 문자:
char,signed char,unsigned char - 정수: 아래의 키워드 3종류에서 하나씩을 조합해서 쓸 수 있습니다. 적어도 하나는 들어가야 합니다.
- 부호:
signed(기본값) 혹은unsigned - 크기:
short,(없음)(기본값),long,long long(C99~) int(생략 가능)
- 부호:
- 이진 부동소숫점: 아래의 키워드 2종류에서 하나씩을 조합해서 쓸 수 있습니다.
- 크기:
float,double,long double - 복소수 여부 (C99~):
(없음)(실수),_Imaginary(허수),_Complex(복소수)#include <complex.h>를 하면_Imaginary를imaginary로,_Complex를complex로 쓸 수 있습니다.- 모든 컴파일러에서 복소수를 지원하는 것은 아니며, 지원할 경우 매크로
__STDC_IEC_559_COMPLEX__(👎 C23~)가, 그렇지 않을 경우__STDC_NO_COMPLEX__(C11~)가 1로 정의되어 있어야 하지만, 왠지 모르게 둘 다 정의되어 있지 않은 컴파일러가 있는 것 같습니다.- 일부 컴파일러에서는
_Complex를 지원하지만_Imaginary는 지원하지 않습니다.
- 일부 컴파일러에서는
- 크기:
- 십진 부동소숫점 (C23~):
_Decimal32,_Decimal64,_Decimal128
참고로 표준 문서에서는 특정한 타입들의 집합에 별도로 이름을 붙여 언급합니다. 이 글에서도 아래 분류를 사용하되, 혼동을 피하기 위해 기울임꼴로 작성하겠습니다.
- 객체(object) 타입: 함수가 아닌 모든 타입
- 문자(character) 타입: 위에서 '문자'로 분류한 타입
- 정수(integer) 타입: 위에서 '문자' 혹은 '정수'로 분류한 타입 및 열거형
- 실수(real) 타입: 정수 타입 및 위에서 '부동소숫점'으로 분류한 실수인 타입
- 산술(arithmetic) 타입: 정수 타입 및 위에서 '부동소숫점'으로 분류한 모든 타입
- 스칼라(scalar) 타입: 산술 타입 및 포인터
- 집합(aggregate) 타입: 배열 및 구조체
- 파생 선언자(derived declarator) 타입: 배열, 함수, 포인터
파생 타입과 복합 타입을 이용해 위 타입들을 여러 방법으로 조합할 수도 있습니다.
char와signed char와unsigned char는 의외로 모두 다른 타입입니다. 정확히는,char는signed char나unsigned char중 하나가 될 수 있지만 컴파일러가 어느 한쪽을 선택할 수 있도록 합니다(implementation-defined).- 정수 타입의 크기는 구현체마다 다릅니다. 정확히는, C 표준에서 타입마다 최소 크기 제한과 크기 관계 제한만 명시하고 있으며 나머지는 자유롭게 정할 수 있습니다.
short와int는 16비트 이상long은 32비트 이상long long은 64비트 이상1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)- 의외로 C 표준에서는 1바이트가 8비트라는 것도 명시하고 있지 않습니다.
파생 타입 [derived type]
특정 연산을 거치면 BaseType이 되는 변수를 선언할 수 있으며, 크게 세 가지가 있습니다.
포인터
BaseType *x;
BaseType 타입의 값을 가리키는 주소를 저장합니다. *x 연산을 거치면 BaseType이 됩니다.
배열
BaseType x[n];
BaseType 타입의 값 n개를 메모리상의 연속적인 위치에 저장합니다. x[i] 연산을 거치면 BaseType이 됩니다.
n이 양수가 아닐 경우 컴파일 오류 혹은 정의되지 않은 동작(VLA일 경우)이 됩니다.n을 생략하면 불완전 타입이 됩니다.
가변 크기 배열 (C99~)
n이 컴파일 타임 상수가 아닐 경우 이를 "가변 크기 배열"(variable-length array, VLA)이라고 하며, VLA의 타입 혹은 여기서 파생되는 타입을 가변 타입5이라고 합니다. 일반 배열과 달리 컴파일 타임에는 크기가 결정되지 않고, 선언문 부분까지 실행될 때에서야 완전히 결정됩니다.
VLA는 선언하면서 초기화를 할 수 없고, 선언한 뒤에 직접 값을 넣어야 합니다.
int x = 5;
int y[x]; // OK: VLA with size x
int z[2*x] = { 0 }; // variable-sized object may not be initialized
모든 컴파일러에서 VLA를 지원하는 것은 아닌데(대표적으로 MSVC가 그렇습니다), 지원하지 않는 컴파일러의 경우 매크로 __STDC_NO_VLA__가 1로 정의되어 있습니다 (C11~).
함수
BaseType x(args...);
일급 객체로 지원되지만 않을 뿐이지, 의외로 함수도 타입으로 볼 수 있습니다. 정해진 타입의 인자를 받아 값을 계산합니다. x(args...) 연산을 거치면 BaseType이 됩니다.
왜 함수 포인터가 없냐고 할 수도 있겠지만, 궁극적으로는 그냥 함수의 포인터이기 때문에 별도 문단으로 작성하지 않았습니다.
- 매개변수 리스트를 생략할 경우(
int x();. 아예 아무것도 없는 경우만을 일컫습니다)에는 명시되지는 않지만 고정된 수의 인자를 받을 수 있습니다(x(123)). 매개변수가void인 경우(int x(void);)에는 명시적으로 인자를 넣을 수 없다는 의미가 됩니다.- K&R C 시절에는 괄호 바깥에 매개변수를 작성했었는데, 표준화가 되면서 괄호 안에 매개변수를 작성하도록 바뀌면서 생긴 레거시라고 합니다. 이 방식의 함수 선언/정의는 C23에서 제거될 예정입니다.
- "명시되지는 않지만 고정된"은 프로그램 전체에서 그 함수에 전달하는 인자의 개수와 타입이 같아야 한다는 의미입니다.
x()와x(123)을 동시에 사용하면 둘 중 적어도 하나의 동작은 정의되지 않습니다.
가변 인자 함수
함수에 매개변수가 하나 이상 있을 경우, 마지막에 매개변수 대신 ...를 하나 더 달면 가변 인자 함수를 만들 수 있습니다. ... 부분에 추가로 전달된 인자는 #include <stdarg.h>를 하고 va_start, va_arg, va_end로 접근할 수 있습니다.
#include <stdarg.h>
// ...
int sum(int count, ...) {
int result = 0;
va_list args;
va_start(args, count);
while(count--)
result += va_arg(args, int);
va_end(args);
return result;
}
암시적 타입 변환에서 자세히 살펴보겠지만, ... 부분에 float를 전달하면 double로, 비트 필드를 포함해 부호 유무와 무관하게 int보다 작은 정수 타입을 전달하면 int 혹은 unsigned int로 변환됩니다. printf 함수에서 float와 double을 구분 없이 %f로 출력하는 것도 이런 이유입니다. float _Complex와 float _Imaginary는 변환되지 않습니다.
파생 타입 조합하기
위에서 확인했듯이 파생 타입도 임의의 순서로 조합할 수 있습니다. 예를 들어...
int *x[10];
이라고 적었을 경우 *x[1]을 하면 int가 됩니다. 즉, x는 int의 포인터의 배열입니다. 이렇게 적으면 어떤 순서로 읽어야 되는지 정말 헷갈리는데(*이 먼저? []이 먼저?), 웬만한 상황에서 통하는 간단한 규칙이 있습니다.
후위 연산자가 전위 연산자보다 우선순위가 높다.
웬만한 언어들의 연산자 우선순위 표에서 이러한 경향성을 찾아볼 수 있었습니다(경향성입니다. 물론 예외가 있습니다). 잠깐 삼천포로 빠지자면, 예를 들어 C의 연산자 우선순위 중 단항 연산자 부분은 이렇습니다.
- (후위 연산자)
- 후위 증감
++/-- - 함수 호출
() - 배열 참조
[] - 구조체/공용체 멤버 참조
. - 포인터를 통한 멤버 참조
->
- 후위 증감
- (전위 연산자)
- 전위 증감
++/-- - 단항 부호
+/- - 논리 NOT
! - 비트 NOT
~ - 타입 변환
(Type) - 역참조
* - 주소
& sizeof,_Alignof
- 전위 증감
또 JavaScript에서는 이렇습니다.
- (후위 연산자)
- 멤버 접근
. - 계산된 멤버 접근
[] - 함수 호출
() - 조건부 체이닝6
?. - 인자 목록 있는
new ...()(이것과new ...는 예외로 치겠습니다)
- 멤버 접근
- 인자 목록 없는
new ... - (후위 연산자) 후위 증감
++/-- - (전위 연산자)
- 논리 NOT
! - 비트 NOT
~ - 단항 부호
+/- - 전위 증감
++/-- typeof,void,delete,await
- 논리 NOT
정확한 이유는 모르겠지만, 일단 저는 -f()을 (-f)()으로 해석하면 곤란하다는 논리로 받아들이고 있습니다.
다시 타입 시스템 얘기로 돌아오자면, C의 파생 타입에는 크게 3가지가 있었고 하나는 전위, 나머지는 후위입니다.
- 포인터
*x(전위) - 배열
x[](후위) - 함수
x()(후위)
괄호가 없으면 후위가 먼저고 전위가 나중이기 때문에, 포인터 연산 직후에 배열/함수 연산을 해야 한다면 괄호가 필요하게 됩니다. 예를 들어 위에서 언급한 int의 포인터의 배열 int *x[10];과 달리 int (*x)[10];은 int의 배열의 포인터입니다.
같은 논리로 왜 함수 포인터를 선언하려면 괄호가 하나 더 필요한지도 설명할 수 있습니다. int (*x)()는 int를 반환하는 함수의 포인터인데, 명백하게 포인터 연산이 먼저고 함수 호출이 나중이기 때문에 연산자 우선순위에 따라 괄호가 필요합니다. int *x()라고 썼다면 포인터를 반환하는 함수로 취급되었을 것입니다.
그런데 이런 체계에서는 타입이 복잡해질수록 한눈에 알아보기가 어렵습니다. 바로 아래에 악명높은 C 타입 읽기를 별도로 설명하겠습니다.
C 타입 쉽게 읽는 법
🙋♂️ 오래 기다리셨습니다! 이 문단에서 1번 떡밥을 회수합니다.
int (*x[8][64])(char *)를 예로 들어보겠습니다. 아래의 단계들을 하나씩 밟아나가며 하나의 영어 문장을 완성합니다.
- 식별자를 찾은 뒤 거기서부터 파생 타입을 읽기 시작한다.
- "
xis a..."
- "
- 오른쪽으로 훑으면서 파생 타입이 보일 때마다 차례대로 추가한다. 닫는 괄호가 보이거나 선언이 끝나면 멈춘다.
- "
xis a[8]of[64]of..."
- "
- 왼쪽으로 훑으면서 똑같은 작업을 한다. 여는 괄호가 보이거나 선언이 끝나면 멈춘다.
- "
xis a[8]of[64]of*of..."
- "
- 지금까지 읽은 선언이 괄호로 감싸져 있을 경우 2번으로 돌아간 뒤 마지막으로 읽은 여닫는 괄호부터 읽는다.
- "
xis a[8]of[64]of*of(char *)of..." - 1~4번의 내용은 "우선순위에 따라 읽는다"로 요약할 수 있습니다.
- "
- 더 이상 읽을 것이 없으면
BaseType으로 마무리한다.- "
xis a[8]of[64]of*of(char *)ofint"
- "
이 문장을 자연어로 바꾸거나("x is an array of size 8×64 of pointer to function (char *) returning int"), 한국어가 더 익숙하다면 완성된 문장을 거꾸로 읽어서 "int를 반환하는 함수 (char *)의 포인터 8×64개짜리 배열"(😱)로 만들 수 있고, 영어 문장 기준으로 등장하는 순서대로 연산하면(즉, [] 다음에 [] 다음에 * 다음에 ()의 순서대로 벗겨내면) BaseType인 int를 얻을 수 있습니다. 이때 가장 왼쪽에 있는 파생 타입이 가장 먼저 벗겨지므로 편의상 "최외곽 타입"이라 하겠습니다. (국어사전에 없는 단어긴 하지만 한자 뜻은 맞지 않나요? 아닌가?)
이렇게 읽어낸 타입을 도로 C 문법으로 돌려놓는 것도 간단합니다. 왼쪽부터 우선순위에 맞게 달아놓은 뒤([]과 ()는 오른쪽, *는 왼쪽에 추가합니다. * 다음에 []이나 ()가 와야 한다면 괄호를 씌웁니다.) 가장 왼쪽에 BaseType을 적으면 됩니다.
시간이 남는다면 다른 타입에도 연습해보는 게 어떨까요? 아래의 타입을 편한 방식으로 읽어 봅시다. 답은 주석에 있습니다.
float **x[4][8];7int *(*foo)(int []);8char **(*(*z)[123])[456];9int *(*(*x)(char *))[64];(이 글의 맨 위에서 얘기했던 그 선언문입니다.)10
함수와 매개변수
사실 C의 함수 원형/정의도 위에서 설명한 타입 시스템으로 나타낼 수 있습니다.
char *foo();
문자열을 반환하는 전형적인 함수입니다. 이것도 선언이라고 치고 읽으면(선언이 맞긴 하지만) 다음과 같습니다.
foois a()of*ofchar.
즉, "char의 포인터(aka 문자열)를 반환하는 함수"입니다. 또 declarator의 모양대로 *foo()를 하면 char가 됩니다. 위에서 작성했던 내용과 완전히 일치하네요!
아니면, 배열의 포인터를 반환하는 함수도 작성할 수 있을까요? 물론이죠.
int (*bar())[8]; // a () of * of [8] of int
다만 타입 조합을 아무렇게나 할 수는 없고, 제한이 있습니다.
- 함수의 배열을 만들 수 없습니다. 함수 포인터의 배열은 가능합니다.
int foo[8](); // 'foo' declared as array of functions of type 'int ()' - 함수는 배열이나 함수를 반환할 수 없습니다. 이를 우회하려면 최외곽 타입을 배열이라면 포인터로, 함수라면 함수 포인터로 고치면 됩니다.
int foo()[5]; // function cannot return array type 'int [5]' int *foo() ; // OK, decayed into 'int *' char ( *bar()[2])(int); // function cannot return array type 'char (*[2])(int)' char (**bar() )(int); // OK, decayed into 'char (**)(int)' int baz(int x) (int); // function cannot return function type 'int (int)' int (*baz(int x))(int); // OK, decayed into 'int (*)(int)' - 함수의 매개변수로도 포인터만을 전달할 수 있습니다. 코드상에는 함수와 배열을 허용하지만, 컴파일될 때 최외곽 타입이 배열일 경우 포인터로, 함수일 경우 함수 포인터로 일괄 변환됩니다.
int foo(int *a, int b[], int c (int), int d [4][4]); // converted to: int foo(int *a, int *b, int (*c)(int), int (*d) [4]);
배열과 함수는 포인터로 바뀐다
🙋♂️ 이 문단에서 2번 떡밥을 회수합니다.
위에서 살펴보았던 조합 제한을 살펴보면 배열을 포인터로, 함수를 함수 포인터로 바꾸는/바꿔야 하는 동작이 공통적으로 보입니다. C++를 깊게 배우신 분이라면 뭔가 익숙할 것 같네요! 사실 C 표준에 따르면 이런 동작은 일부 예외를 제외하고 표현식을 다루는 모든 상황에서 발생합니다. C23 표준에서 6.3.2.1의 일부분을 한국어로 번역하면 다음과 같습니다.
(/3)
sizeof연산자, 단항&연산자의 피연산자이거나 문자열 리터럴로서 배열을 초기화할 때를 제외하면 "type의 배열" 타입을 가지는 표현식은 배열 객체의 첫 원소를 가리키는, "type의 포인터" 타입을 가지는 표현식으로 변환되며, 이는 좌측값11이 아니다. 그 배열 객체가 레지스터 기억 영역 분류를 가질 경우의 동작은 정의되지 않는다.(/4) 함수 지시자12란 함수 타입을 가지는 표현식을 말한다.
sizeof연산자나 typeof 연산자, 단항&연산자의 피연산자일 때를 제외하면 "type을 반환하는 함수" 타입을 가지는 함수 지시자는 "type을 반환하는 함수의 포인터" 타입을 가지는 표현식으로 변환된다.
위의 두 조항은 결국 "배열과 함수는 일급 객체가 아니다"로 귀결됩니다. 배열과 함수는 선언만 할 수 있고 대입하려고 하면 포인터로 바뀌기 때문에 대입할 수 없습니다. 자연스럽게 복사할 수도 없게 됩니다. 과거에는 배열을 통째로 복사하는 게 느려서 배열 복사를 최대한 지양해야 했고, 함수는 애초에 고정된 크기가 없어 복사도 불가능하니 포인터를 대신 넘기도록 했을 거라는 추측이 가능하겠습니다. 이외에도 포인터, 배열, 함수에 관한 여러 가지 특이한 동작도 이 두 조항으로 인한 것입니다.
- 배열의 이름이 첫 원소의 포인터처럼 동작한다.
- /3에 명시된 동작입니다.
- 함수 포인터를 초기화할 때
&를 쓰지 않아도 된다.- 함수의 이름만 써도 /4에 의해 함수 포인터로 변환되기 때문에 같은 타입이 됩니다.
&를 사용할 경우 예외 조항에 의해 함수의 주소를 얻게 되므로 여전히 함수 포인터가 됩니다.
- 함수 포인터를 함수처럼, 포인터를 배열처럼 쓸 수 있다.
- 이미 함수가 함수 포인터로, 배열이 포인터로 바뀌었기 때문입니다.
int arr[8], *ptr_to_arr = arr; // by 6.3.2.1/3 arr[4]; ptr_to_arr[4]; // pointer access arr + 4; ptr_to_arr + 4; // pointer arithmetic int fn(), (*fn_ptr)() = fn; // by 6.3.2.1/4 fn(); fn_ptr(); // pointer call - 함수 포인터를 무한정 역참조할 수 있다.
- 함수 포인터는 역참조해도 /4에 의해 도로 함수 포인터가 되기 때문입니다.
(**********************fn)(); // same as fn();
"배열과 포인터가 비슷하다"는 이야기가 이것 때문에 나오는 것 같습니다. 위의 이유로 비슷하게 쓸 수 있는 것뿐이지, 배열과 포인터는 전혀 다른 타입입니다.
응용: malloc 한 번으로 다차원 배열 동적 할당하기
🙋♂️ 이 문단에서 3번 떡밥을 회수합니다.
2차원 배열 동적 할당은 보통 아래와 같은 방법으로 배웠을 겁니다.
int **array_2d = malloc(n*sizeof(int *));
for(int i = 0; i < n; i++)
array_2d[i] = malloc(m*sizeof(int));
malloc을 n+1번 호출합니다. 비정형 배열13을 의도한 것이라면 저 방법이 맞겠지만, 그렇지 않으면 꽤 비효율적인 코드입니다. 나중에 다 쓰고 반환할 때도 free를 n+1번 호출해야 하고, n+1번 malloc받은 공간이 연속이라는 보장도 없습니다.
그렇다고 int **array_2d에 무턱대고 2차원 배열 전체를 malloc할 수도 없습니다(배열의 포인터와 포인터의 포인터는 다릅니다). 제가 과거에 함수에서 2차원 배열을 int **로 받으려다가 포기하고 void *로 바꿔서 전달했던 적이 있었습니다.
지금까지 배운 타입 시스템을 잘 활용하면 대신 이런 코드를 짤 수 있습니다.
int (*array_2d)[m] = malloc(n*sizeof(int [m]));
우리가 궁극적으로 만들고자 하는 배열은 int array_2d[n][m];처럼 동작해야 합니다. "a [n] of [m] of int"인데, 동적 할당을 해야 하니 [n]은 쓸 수 없습니다.
다행히 malloc은 연속된 공간을 할당해주기 때문에 배열과 다름없이 쓸 수 있으니 최외곽에 [n] 대신 *을 써서(6.3.2.1/3에 의해 항상 이루어지던 변환입니다!) "a * of [m] of int", 즉 int (*array_2d)[m];으로 대신 선언할 수 있습니다. 나머지는 malloc에 맡깁시다.
어차피 int [n][m]은 int [m] n개나 int n×m개를 연속으로 이어붙인 것이나 다름없으므로 malloc에 전달할 사이즈는 sizeof(int [n][m]), n*sizeof(int [m]), n*sizeof *array_2d, n*m*sizeof(int), n*m*sizeof **array_2d 중 뭐든 상관없습니다.
물론 3차원 이상의 배열도 이렇게 할당할 수 있습니다. 쓸 일이 자주 있을지는 모르겠네요.
int (*array_3d)[b][c] = malloc(a*sizeof(int [b][c]));
int (*array_4d)[b][c][d] = malloc(a*sizeof(int [b][c][d]));
// ...
응용: 사실 C++도 대체로 같습니다
이 문단은 2021년 10월 11일에 추가로 작성했습니다.
개인적으로 엄청나게 복잡한 C++를 싫어하지만, 위의 타입 조합에 관한 내용은 C++에도 대체로 비슷하게 적용됩니다. 자세히 얘기하자면 다음과 같습니다.
- C 스타일로 작성할 수 있는 파생 타입은 아래와 같이 5가지입니다.
- 포인터
BaseType *x; - 배열
BaseType x[n]; - 함수
BaseType x(args...);BaseType x();라고 선언했는데 클래스BaseType의 기본 생성자(BaseType::BaseType())가 호출되지 않는 것도 매개변수가 없고BaseType을 반환하는 함수로 해석되기 때문입니다.14
- 좌측값 참조
BaseType &x; - 우측값 참조
BaseType &&x;(C++11~) (참조의 참조가 아닙니다!)
- 포인터
- (배열이나 함수)의 (포인터나 참조)를 만들려면 괄호가 필요합니다.
BaseType &x();는 참조를 반환하는 함수이고,BaseType (&x)();은 함수에 대한 참조입니다.
- C 타입 읽듯이 읽을 수도 있습니다.
- 함수의 배열을 만들 수 없습니다. 함수의 참조는 가능합니다.
- 함수는 배열이나 함수를 반환할 수 없지만, 참조는 반환할 수 있습니다.
- 매개변수로 함수나 배열을 전달하려고 하면 (함수) 포인터로 바뀝니다.
- 참조의 포인터, 참조의 배열, 참조의 참조는 만들 수 없습니다.
- 글의 나중에 나오는 내용이지만 선언에서 식별자를 지우면 타입 이름이 됩니다.
std::set에 비교 함수로 함수 포인터를 전달하고 싶다면std::set<T, bool (*)(const T &, const T &)>처럼 하면 됩니다. - 여담이지만 저는 이런 이유로
int& x;가 아니라int &x;가 맞다고 봅니다.
이외에 C++ 타입 시스템에는 template이나 concept나 ... 같은 게 잔뜩 끼얹어져서 C 타입 시스템과는 거리가 어느 정도 멀어진 감이 있습니다.
새로운 BaseType 만들기
지금까지 BaseType에 기본 타입이 오는 예시만을 들었었는데, 사용자가 직접 새로운 BaseType을 정의할 수 있습니다.
typedef
🙋♂️ 이 문단에서 4번 떡밥을 회수합니다.
typedef 선언의 기본 형태는 다음과 같습니다.
typedef BaseType declarator;
그냥 선언에 typedef만 붙이면 typedef 선언이 되며, 그 타입을 갖는 변수가 아니라 그 타입과 의미가 같은 새로운 타입을 선언합니다. 예를 들어 typedef int *Foo[8];을 하면 타입 Foo는 타입 이름 int *[8]과 같은 의미가, 변수 선언 Foo *x;는 int *(*x)[8];과 같은 의미가 됩니다.
typedef 선언도 한꺼번에 여러 개를 선언할 수 있는데, 이를 잘 활용하면 아래와 같이 연결 리스트 타입을 선언하면서 그 타입에 대한 포인터도 한꺼번에 선언할 수 있습니다.
typedef struct List {
int value;
struct List *next;
} ListNode, *ListPtr;
typedef로 함수 타입도 선언할 수 있고, 타입 체킹도 올바르게 됩니다. 이런 형태는 함수 원형에만 쓸 수 있고, 정의할 때는 괄호가 필요하기 때문에 불가능합니다.
typedef int IntFn(int);
IntFn foo;
int foo(int x) { // OK
return x;
}
int foo(long x) { // conflicting types for 'foo'
return x;
}
IntFn foo { // expected ';' after top level declarator
return 0;
}
typedef도 일반적인 선언과 같이 블록 범위를 가질 수 있습니다. 안쪽에 있는 typedef가 바깥쪽의 typedef를 가립니다.
// sizeof(int) = 4라고 가정합니다.
typedef int foo; // (1); sizeof(foo) = 4
int main() {
typedef int foo[8]; // (2); sizeof(foo) = 32
printf("%ld\n", sizeof(foo)); // 32; bound to (2)
{
typedef int foo[64]; // (3); sizeof(foo) = 256
printf("%ld\n", sizeof(foo)); // 256; bound to (3)
}
printf("%ld\n", sizeof(foo)); // 32; bound to (2)
return 0;
}
재미있는 사실! 의외로 typedef는 이론상 기억 영역 분류 지정자입니다. 물론 typedef는 기억 영역 분류와 관련해 어떤 동작도 하지 않습니다. 위에서 "BaseType은 기억 영역 분류 지정자를 포함하며, 순서는 상관 없다"고 했던 걸 생각하면 의외로 이렇게도 할 수 있습니다.
int typedef long foo; // = typedef long foo;
이 글을 쓰면서 벌써 여러 번 하는 얘기지만... 하지 말아주세요.
복합 타입
복합 타입 선언은 크게 이름 부분과 정의 부분으로 나뉘고, 포함하느냐 마느냐에 따라 서로 다른 의미를 갖습니다. 아래 세 종류의 구문 모두 BaseType으로 취급되기 때문에 변수 선언까지 할 수 있습니다.
- 이름만 쓰면 함수처럼 선언만 하거나(이미 선언되지 않았을 경우), 변수 선언 시
BaseType으로 사용할 수 있습니다. 정의는 나중에 별도로 작성할 수 있습니다.struct Foo; // OK, introduces struct Foo struct Foo x; // OK, declares x of type 'struct Foo' struct Foo; // also OK, declares no variables - 정의만 쓰면 익명 타입이 됩니다. 나중에 이 타입의 변수를 더 이상 만들 수 없습니다.
- 이 경우 변수 선언을 하지 않으면 사실상 무의미한 구문이 됩니다.
- 서로 다른 선언문에서 선언한 익명 구조체/공용체끼리는 정의가 완전히 같더라도 대입할 수 없습니다.
- 정의가 완전히 같은 익명 열거형은 원소가 중복되므로 만들 수 없습니다.
struct { // (1) int x; } a, b; b = a; // OK, a and b are from same declaration struct { // (2) int x; } c = a; // initializing 'struct (anonymous struct at (2))' with an expression of incompatible type 'struct (anonymous struct at (1))' - 이름과 정의를 모두 쓰면 선언하는 동시에 정의합니다. 여러 번 정의할 수 없습니다.
struct Foo { int x; }; // OK struct Foo { int x; }; // redefinition of 'Foo' - 이름과 정의 모두 생략할 수는 없습니다.
struct; // declaration of anonymous struct must be a definition
일단 선언하고 나면 다음과 같은 형태로 쓸 수 있습니다. 실제로 변수 선언에 사용하려면 이전 위치에서 정의를 끝마친 상태여야 합니다.
- 구조체:
struct Foo(Foo가 아닙니다!) - 공용체:
union Foo - 열거형:
enum Foo
실제 이름 앞에 struct/union/enum 부분이 공통적으로 들어가는데, 이 부분을 떼고 Foo로만 쓰려면 명시적으로 typedef를 해야 합니다. 또한 이름만 같은 struct/union/enum 타입을 동시에 정의할 수는 없습니다.
struct Foo {}; // OK, defines struct Foo
typedef struct Foo Foo; // OK, Foo = struct Foo
union Foo {}; // use of 'Foo' with tag type that does not match previous declaration
복합 타입도 일반적인 선언이나 typedef와 같이 블록 범위를 가질 수 있습니다. 안쪽에 있는 타입이 바깥쪽의 타입을 가립니다.
enum Foo { a, b, c };
int main() {
enum Foo { d, e, f };
enum Foo foo = e; // OK, second variant of inner 'enum Foo'
foo = a; // implicit conversion from enumeration type 'enum Foo' to different enumeration type 'enum Foo'
return 0;
}
구조체
구조체는 여러 개의 멤버를 하나의 타입으로 묶은 자료구조입니다. 모든 멤버는 각각 고유한 값을 가질 수 있습니다.
빈 구조체(엄밀히는 이름이 붙은 멤버가 없는 구조체)를 정의하려고 하면 정의되지 않은 동작이 되며, 공용체에 대해서도 같습니다. GCC 등 일부 컴파일러에서는 언어 확장으로 빈 구조체를 지원하고 있습니다.
struct EmptyStruct {}; // UB
비트 필드
구조체 내부에서는 비트 필드 기능을 이용해 변수를 비트 단위로 끊어서 사용하는 것이 가능합니다. 비트 필드에 사용할 수 있는 타입은 다음과 같습니다.
unsigned int및signed intint: 비트 필드 맥락에서는char처럼unsigned나signed중 하나가 될 수 있습니다._Bool- 이외 컴파일러에서 지원하는(implementation-defined) 타입
멤버 변수 옆에 : (비트 수)를 추가함으로써 그만큼의 비트만 사용하는 멤버를 선언할 수 있습니다. 같은 선언문에서와 선언했는지와 무관하게 비트 필드 변수가 연속될 경우 메모리에서 연속된 비트를 사용합니다. 비트 수는 기반으로 하는 타입의 비트 수를 초과할 수 없습니다.
// int가 32비트임을 가정합니다.
struct Foo {
unsigned int
a: 7, // 7 bits; 0...127
b: 3; // 3 bits; 0...7
// 22 bits unused
unsigned int c: 33; // width of bit-field 'c' (33 bits) exceeds width of its type (32 bits)
};
변수명을 생략하면 원하는 수의 비트를 "낭비할" 수 있습니다.
struct Foo {
unsigned int
: 7, // 7 bits unused
b: 3; // 3 bits; 0...7
// 22 bits unused
};
0비트짜리 비트 필드를 선언하면 그 다음 비트 필드 변수는 연속된 비트를 사용하지 않고 강제로 새로운 비트를 사용합니다. 이때는 변수명을 반드시 생략해야 합니다.
struct Foo {
unsigned int
x: 4, // 4 bits; 0...15
: 0, // 28 bits unused; continue to next unsigned int
y: 4; // 4 bits; 0...15
// 28 bits unused
};
유연 배열 멤버 [flexible array member] (C99~)
구조체에 멤버가 하나 이상 있을 경우, 마지막에 불완전한(즉, 크기를 생략한) 타입의 배열 멤버를 하나 더 선언할 수 있습니다. 이때 구조체의 크기는 마지막 배열을 포함하지 않으며, 그 크기 이상의 메모리를 할당할 경우 남은 공간은 마지막 배열 멤버를 통해 접근할 수 있습니다.
struct Foo {
int x, y[];
};
// struct Foo, but y behaves like int [4]
struct Foo *foo = malloc(sizeof(struct Foo) + 4*sizeof(int));
foo->y[3] = 123;
익명 구조체/공용체 멤버 (C11~)
구조체/공용체 안에 익명 구조체/공용체 멤버를 선언할 때는 멤버의 이름을 생략할 수 있습니다. 이때는 안쪽 멤버를 바깥쪽 멤버인 것처럼 사용할 수 있습니다. 중첩도 가능합니다.
struct Foo {
struct {
int a;
int b;
}; // anonymous struct
int c;
};
struct Foo foo;
foo.a = 1; // foo.(anonymous).a
foo.b = 2; // foo.(anonymous).b
foo.c = 3; // foo.c
공용체
구조체와 같이 여러 개의 멤버를 선언할 수 있지만, 모든 멤버가 같은 메모리를 공유하며 한 멤버에 대입하면 다른 멤버의 값을 덮어씁니다.
union Foo {
char x, y[16];
};
union Foo foo;
strcpy(foo.y, "foo");
// foo.x is now 'f'
열거형
구조체와 공용체와는 조금 다른데, 여러 가지 원소를 정의하고 그 중에 하나를 사용할 수 있도록 합니다. 내부적으로는 그 열거형의 모든 값을 표현할 수 있는 정수 타입 중 컴파일러가 정하는(implementation-defined) 타입처럼 동작합니다.
enum Foo {
// 원소 1개 이상
Bar,
Baz,
Quux
};
enum Foo foo = Bar;
foo = 5; // OK
열거형의 첫 원소의 값은 0이며, 따로 정하지 않을 경우 (이전 원소의 값) + 1의 값을 가집니다. = (값)을 추가해서 강제로 다른 값으로 설정할 수 있습니다.
enum Foo {
A, // 0
B, // 1
C = 123, // 123
D // 124
};
열거형의 모든 원소 역시 같은 범위 내에서 같은 이름으로 사용할 수 있으므로, 같은 범위 내의 변수명이나 다른 열거형 원소와 중복될 수 없습니다.
{
int x; // OK
enum { x }; // redefinition of 'x'
}
{
enum { x }; // OK, introduces x
enum { x }; // redefinition of enumerator 'x'
}
빈 열거형은 만들 수 없습니다. 위의 빈 구조체/공용체와 달리 GCC에서도 언어 확장으로 지원하지 않습니다.
enum Foo {}; // use of empty enum
불완전 타입 [incomplete type]
변수를 메모리에 할당하려면 타입의 크기를 알아야 하는데, 충분한 정보가 없어 크기를 결정할 수 없는 경우도 있습니다. 이런 상태의 타입을 불완전 타입이라고 합니다. 불완전 타입은 선언이나 타입 변환 등 대부분의 타입을 요구하는 곳에 사용할 수 없습니다.
불완전 타입은 다음과 같이 크게 세 종류로 나뉩니다. 불완전 타입을 완전한 타입으로 만드는 것을 "완성한다"고 하겠습니다.
void- 완성할 수 없습니다.
- 크기를 생략한 배열
[]- 배열/문자열 리터럴로 초기화할 경우 그 리터럴을 담을 수 있는 가장 작은 크기로 완성됩니다.
- 나중에 크기를 생략하지 않고 다시 선언할 경우 그 크기로 완성됩니다.
- 정의를 마치지 않은 복합 타입
- 정의를 마치는 순간(즉, 중괄호
{ ... }가 닫히는 순간) 완성됩니다. 그 타입을 참조하지만 이전 위치에 있는 타입은 완성되지 않은 상태로 남습니다.
- 정의를 마치는 순간(즉, 중괄호
타입의 완전성에 따라 파생 여부 역시 나뉩니다.
- 불완전 타입의 포인터를 만들 수 있습니다.
- 불완전 배열 포인터의 역참조를 제외하면 타입의 크기가 필요한 연산(
++,*등)은 할 수 없습니다.
- 불완전 배열 포인터의 역참조를 제외하면 타입의 크기가 필요한 연산(
- 불완전 타입의 배열은 만들 수 없습니다.
- 다차원 배열에서 가장 왼쪽(최외곽)의 크기만 생략할 수 있는 것(
int x[][1][2][3];)도 이런 이유입니다.
- 다차원 배열에서 가장 왼쪽(최외곽)의 크기만 생략할 수 있는 것(
- 불완전 타입을 반환하는 함수는 만들 수 없습니다.
void를 "반환하는" 함수는 예외이며, 아무 것도 반환하지 않아야 합니다.return문을 사용할 경우 반환값을 생략한return;형태만 허용됩니다.
타입 이름 [type name]
지금까지 C 타입을 '선언 형태'로만 작성했는데, 가끔씩 식별자가 없는 다른 형태로 타입을 작성해야 할 필요가 있습니다.
int *x;
return (void *)y;
2번째 줄과 같은 모양을 타입 이름이라 하는데, 선언 형태에서 식별자만 지우면 됩니다! 예를 들어 int (*x[8])(void);의 타입 이름은 int (*[8])(void)가 됩니다.
단 이 방법이 먹히지 않을 때가 있는데, 식별자가 단독으로 괄호로 둘러싸여 있었다면(int (foo)(void);) 식별자를 지우고 나서는 함수 괄호로 취급됩니다(int ()(void), aka () of (void) of int). 식별자가 없어지면서 빈 괄호에 다른 의미가 부여된 건데, 이런 현상을 막기 위해서 불필요한 괄호는 지우는 것을 권장드립니다.
이미 예상하셨겠지만, 저는 이런 이유로 sizeof(int*)조차도 sizeof(int *)가 맞다고 봅니다. 물론 sizeof(int )가 맞다고 우기기까지 하지는 않습니다.
범위 [scope]
원래는 글에 포함하지 않으려고 했는데, 이곳저곳에서 언급하니까 한 번쯤 짚고 넘어가야 할 것 같네요. 시작하자마자 이 얘기부터 하면 읽다가 튕겨져나가는 분들이 많을 것 같아 중간에 끼워넣었습니다.
C에서 모든 식별자는 범위를 가지며, 그 범위 안에 있는 코드만 그 식별자를 사용할 수 있습니다. C에는 크게 두(+2) 가지의 범위가 있습니다. typedef와 복합 타입 선언을 포함해 모든 선언은 아래의 범위 규칙을 따릅니다.
블록 범위
블록({ ... }, 매개변수와 함수 본문을 포함합니다) 안에 선언한 식별자는 선언이 끝나는 곳부터(초기화가 될 경우에는 초기화 표현식 바로 앞부터) 그 블록이 끝날 때까지 사용할 수 있습니다. 안쪽 블록과 바깥쪽 블록에서 같은 식별자를 선언한 경우 안쪽이 바깥쪽을 가립니다.
int x = 5;
{
int x = 7;
printf("%d", x); // 7
} // scope of the latter x ends here
printf("%d", x); // 5
if문, switch문, for문, while문, do-while문도 별도의 블록 범위를 생성하며, 본문의 블록 범위를 공유하지 않습니다. (C99~) 매개변수의 범위는 함수 본문의 블록 범위를 공유합니다.
for(int i = /* scope of i begins here */ 0; i < 10; i++) {
foo(i); // OK
} // scope of i ends here
foo(i); // use of undeclared identifier 'i'
열거형 원소도 열거형의 범위를 따르지만, 다른 선언문과는 달리 범위가 = 식 뒤부터 시작됩니다. 즉, 이전에 선언했던 같은 이름의 열거형 원소를 참조할 수 있습니다.
enum { x = 5 };
{
enum {
x = x + 1 /* scope of the latter x begins here */, // 6
y // 7
};
}
파일 범위
그렇지 않은 식별자는 선언이 끝나는 곳부터 파일이 끝날 때까지 사용할 수 있습니다. 파일 범위로 선언된 변수는 흔히 "전역 변수"라고도 합니다.
함수 범위
함수 안의 레이블은 그 함수의 본문 전체(레이블보다 앞인 위치를 포함합니다)에서 가리킬 수 있습니다.
void foo() { // scope of label begins here
goto label;
{
label:;
}
goto label;
} // scope of label ends here
함수 원형 범위
함수 원형에서 매개변수를 정의할 때 이전 매개변수를 참조할 수 있습니다.
int foo(
int a, int b,
int arr[a][b] // OK
);
기억 영역 분류 [storage class]
C에는 auto, register, static, extern, _Thread_local (C11~)의 다섯 종류의 기억 영역 분류 지정자가 있습니다. 위에서 언급했듯이 이론상으로는 typedef도 기억 영역 분류 지정자지만 기억 영역과는 무관한 동작을 하기 때문에 제외합니다.
기억 영역 분류는 크게 기억 기간과 연결성으로 나뉩니다. 위에서 언급한 다섯 종류의 지정자를 알아보기 전에 먼저 살펴봅시다.
기억 기간
기억 기간은 객체의 메모리 공간이 언제 할당되고, 반환되는지를 결정합니다.
- 자동(automatic): 그 객체가 선언된 블록에 들어오는 순간(단, VLA는 선언문이 실행될 때) 할당되고, 어떤 방법으로든 나가는 순간 반환됩니다.
- 일반적으로 사용하는 "지역 변수"가 자동입니다.
- 흔히 "스택에 할당되었다"고 합니다.
- 정적(static): 프로그램이 실행되는 내내 할당된 상태를 유지하며,
main함수가 실행되기 전에 단 한 번만 초기화됩니다.- 함수에서 나가도 없어지지 않기 때문에 이전의 값을 "기억"하는 것처럼 보입니다.
- 흔히 "
.data/.bss세그먼트에 할당되었다"고 합니다.
- 스레드(thread) (C11~): 스레드가 실행되는 내내 할당된 상태를 유지하며, 스레드가 생성되었을 때 초기화됩니다. 각 스레드는 이 객체에 해당하는 메모리 공간을 따로 할당합니다.
- 할당(allocated):
malloc등의 함수를 통해 직접 할당받거나 반환할 수 있습니다. 기억 영역 분류 지정자와는 무관합니다.- 흔히 "힙에 할당되었다"고 합니다.
연결성
연결성은 식별자를 다른 범위에서 사용할 수 있는지의 여부를 결정합니다. 한 파일 내에서 한 식별자가 내부 연결성과 외부 연결성을 동시에 띨 수 없습니다.
- 연결성 없음: 해당 식별자의 범위에서만 사용할 수 있습니다.
- 연결성 없이 선언되었을 경우 식별자가 같아도 모두 다른 것을 가리킵니다.
- 내부 연결(internal linkage): 해당 식별자가 있는 파일 전체에서 사용할 수 있습니다.
- 정확히 말하자면, 특정한 파일에서 내부 연결성으로 선언되었을 때, 식별자가 같다면 같은 것을 가리킵니다.
- 외부 연결 (external linkage): 다른 파일을 포함해 프로그램 전체에서 사용할 수 있습니다. 링크 단계에서 외부 연결성을 지닌 식별자 참조끼리 연결됩니다.
- 정확히 말하자면, 컴파일에 사용된 모든 파일에서 외부 연결성으로 선언되었을 때, 식별자가 같다면 같은 것을 가리킵니다.
블록 범위에서 외부 연결성으로 선언했을 때는 조금 복잡한 규칙을 추가로 따르는데,
- 기존에 선언했던 같은 식별자 중 "보이는"(연결되는) 것이
static이나extern이라면, 그 식별자의 연결성을 상속받습니다. - 그렇지 않을 경우 그 식별자는 외부 연결성을 띱니다.
이 규칙을 활용해 같은 파일 내라도 extern을 사용해 더 나중에 선언했거나 다른 블록에 가려진 기존의 식별자와 연결할 수 있습니다. 물론 애초에 다른 이름을 짓는 게 편합니다.
extern int a; // (1), external linkage
static int b; // (2), internal linkage
void foo() {
int a; // (3), no linkage
int b; // (4), no linkage
{
extern int a; // OK, refers to (1)
// ↑ 기존에 보이는 식별자 (3)이 `static`이나 `extern`이 아니므로
// 이 선언은 외부 연결성을 띱니다.
// 이는 기존의 (1)과 충돌하지 않습니다.
extern int b; // variable previously declared 'static' redeclared 'extern'
// ↑ 이 선언도 (4)에 의해 외부 연결성을 띱니다.
// 이는 기존의 (2)와 충돌하므로 오류가 발생합니다.
}
}
기억 영역 분류 지정자 [storage-class specifier]
기억 영역 분류 지정자를 명시하면 변수의 생명주기가 어떻게 되는지(기억 기간), 어디서 사용할 수 있는지(연결성)를 나타낼 수 있습니다.
auto/register: 자동 기억 기간을 가지고, 연결성은 없습니다.auto와 달리register변수는 컴파일러에게 CPU 레지스터를 사용하도록 최적화 힌트를 남깁니다. 실제로 최적화가 이루어지는지와 무관하게&연산자를 사용할 수 없습니다.
static: 정적 기억 기간을 가지고, 파일 범위일 때에만 내부 연결성을 가집니다.extern: 정적 기억 기간과 외부 연결성을 가집니다._Thread_local(C11~): 스레드 기억 기간을 가집니다.- 연결성은 아래의 두 형태 중 하나를 사용해 명시할 수 있습니다. 블록 범위 변수일 경우 반드시 명시해야 합니다.
static _Thread_local: 내부 연결성을 가집니다.extern _Thread_local: 외부 연결성을 가집니다.
#include <threads.h>를 하면thread_local로 쓸 수 있습니다.
- 연결성은 아래의 두 형태 중 하나를 사용해 명시할 수 있습니다. 블록 범위 변수일 경우 반드시 명시해야 합니다.
어떤 선언인지에 따라 어떤 기억 영역 분류를 쓸 수 있는지가 나뉩니다. 생략하면 기본값이 적용됩니다.
- 파일 범위 함수는
extern(기본값)과static으로 선언할 수 있습니다. - 블록 범위 함수 선언은
extern(기본값)으로만 선언할 수 있습니다. - 파일 범위 변수는
extern(기본값),static,_Thread_local로 선언할 수 있습니다. - 블록 범위 변수는
auto(기본값),register,static,extern,_Thread_local로 모두 선언할 수 있습니다. - 매개변수는
register로 선언할 수 있습니다. 기본값은auto이지만, 명시적으로auto로 선언할 수는 없습니다.
한정자 [qualifier]
C에는 세 종류의 한정자가 있으며, 한정자가 붙은 타입은 값을 읽거나 쓸 때의 성질을 바꾸고 컴파일러 최적화에 관여합니다.
여기서는 "qualifier"를 "한정자"로 번역하기로 했으니 "const-qualified"(const 한정자가 추가된 타입)도 "const 한정되다"로 번역하겠습니다.
한정자가 붙는 위치
🙋♂️ 이 문단에서 5번 떡밥을 회수합니다.
BaseType에 붙는 경우, 이미 알아봤듯 아무 위치에 추가할 수 있습니다. 원래는 개인적으로 BaseType const로 쓰는 것을 선호했지만, 몇 번 써보니 가독성이 떨어지는 것 같아 const BaseType으로 선회했습니다.
포인터에 붙는 경우 포인터의 바로 뒤에 붙습니다(* const 혹은 *const). Rust를 써본 적이 있다면, rustfmt에서 참조에 mut 키워드를 붙이는 규칙과 같다(&mut)고 이해하면 외우기 쉽습니다. 개인적으로 C에서도 의도를 명확히 전달하기 위해 포인터와 한정자 사이를 띄우지 않는 것이 좋다고 생각합니다(*const처럼).
함수의 매개변수에서 최외곽 배열이 포인터로 변환되는 동작을 고려해 배열에도 한정자를 붙일 수 있으며, 이 경우 여는 대괄호 바로 뒤에 붙습니다([const 8]). 매개변수로 사용된 최외곽 배열 이외에는 한정자를 붙일 수 없습니다.
이 위치에는 이외에도 static이 붙을 수 있는데([static 4]. 한정자와의 순서는 상관 없습니다), 이 경우에는 인자로 전달받는 포인터가 정해진 크기 이상인 배열의 첫 원소를 가리켜야 합니다. 여기 말고 언급하기 적당한 곳이 없네요.
void foo(int x[static 4]);
int a[4], b[2];
foo(a); // OK
foo(b); // undefined behavior
함수에는 한정자를 붙일 수 없습니다. 함수 포인터에 한정자를 붙이려면 명시적으로 함수 포인터로 선언해야 합니다.
한정자가 여러 개 붙는다면 같은 위치에 띄어쓰기로 구분해서 넣으면 됩니다. 순서는 상관 없습니다.
이제 맨 위에서 던졌던 떡밥을 하나 더 회수해 봅시다. 아래의 네 선언은 이렇게 다릅니다.
const int *x;:x는const int의*입니다.x는const가 아니지만,*x는const입니다.int const *x;:x는int const의*입니다. 1번과 같습니다.int *const x;:x는int의*const입니다.x는const이지만,*x는const가 아닙니다.const int *const x;:x는const int의*const입니다.x와*x모두const입니다.
const: "변하지 않음"
const 한정자가 붙은 타입이나, 멤버(중첩된 경우를 포함해서) 중 하나라도 const인 복합 타입에는 쓰기 연산을 할 수 없습니다. 선언할 때 초기화는 허용합니다.
const 한정된 변수는 값이 변하지 않기 때문에, 컴파일러가 읽기 전용 영역에 할당하거나 상황에 따라 아예 하드코딩이 되도록 최적화될 수 있습니다.
const int x = 5;
x = 6; // cannot assign to variable 'x' with const-qualified type 'const int'
struct {
int x;
const int y;
} y = { 1, 5 }, z = { 6, 7 };
y = z; // cannot assign to variable 'y' with const-qualified data member 'y'
y.y = 9; // cannot assign to non-static data member 'y' with const-qualified type 'const int'
const는 쓰기 연산에만 영향을 미치기 때문에 좌측값이 아닌 표현식에서는 효력을 잃습니다.
volatile: "최적화되지 않음"
volatile 한정자가 붙은 타입의 읽기/쓰기 연산은 부작용15으로 취급되며, 최적화 없이 있는 그대로 실행됩니다. 주로 신호가 불안정하거나, 입출력 신호가 메모리 매핑이 되어 있거나, 벤치마크 등 최적화를 해서는 안 되는 상황에 사용합니다. 이건 코드만으로는 보여드릴 수 없으니 컴파일러에서 출력하는 어셈블리를 직접 확인해 봅시다.
Compiler Explorer에서 아래와 같이 volatile 한정자만 다른 두 함수를 -O2 플래그(중간 단계 최적화)를 추가하고 컴파일하면 아래와 같은 결과가 나옵니다. 이미지가 작게 나온다면 우클릭을 하거나 길게 눌러서 원본을 볼 수 있습니다.
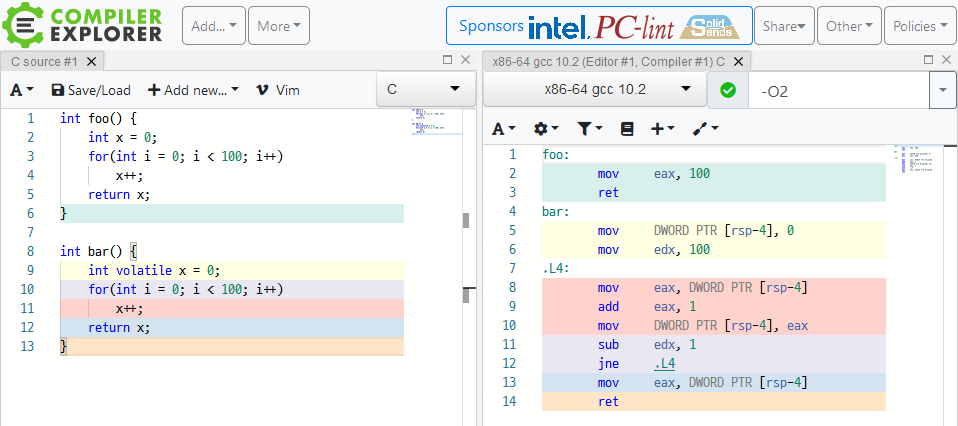
foo(상단의 초록색 블록)는 사실상 return 100;과 동일하게 최적화된 반면, bar(나머지 모든 부분)는 대입과 루프, return x;를 할 때의 읽기 연산까지 그대로 어셈블리로 출력되었습니다.
비volatile 변수를 volatile로 타입 변환해도 volatile의 효과가 발생하지 않으며, 반드시 volatile 타입의 포인터를 통해 접근해야 합니다.
const와 volatile은 상호 독립적이기 때문에 한 변수를 동시에 const/volatile 한정할 수도 있습니다.
restrict (C99~): "접근을 독점함"
😰 여기는 아직도 헷갈리는 부분이 많습니다.
restrict는 객체 타입의 포인터만을 한정할 수 있으며, 좌측값이 아닌 표현식에서는 효력을 잃습니다. C23부터는 객체 타입의 (임의 차원의) 배열도 restrict 한정할 수 있습니다.
restrict int x; // restrict requires a pointer or reference ('int' is invalid)
int (*restrict y)(void); // pointer to function type 'int (void)' may not be 'restrict' qualified
restrict 포인터가 선언된 블록 안에서, 그 포인터가 가리키는 객체가 수정될 경우 그 객체는 그 포인터로만 읽고 써야 합니다. restrict 포인터로 읽기만 하는 경우에는 상관 없습니다. 컴파일러 오류/경고를 통해 최소한의 안전망을 갖추고 있는 const와 volatile과 달리, 위의 조건은 프로그래머가 알아서 충족해야 합니다.
컴파일러는 restrict 포인터가 어떤 포인터와도 다른 객체를 참조한다고 가정하고 최적화할 수 있습니다. 예를 들어, 아래 코드의 bar가 restrict 포인터를 받지 않는다고 가정하면 x == y인 경우를 고려해 조금 더 긴 어셈블리가 출력되지만, restrict로 인해 x != y가 보장되므로 어셈블리 출력이 줄어듭니다.
void foo(int *restrict x, int *restrict y) {
int a = *x, b = *y;
}
void bar(int *restrict x, int *restrict y) {
for(int i = 0; i < 8; i++)
*x += *y;
}
int a = 0, b = 0;
foo(&a, &a); // OK, only read operations
bar(&a, &b); // OK, each argument points to different object
bar(&a, &a); // undefined behavior
파생 타입과의 관계
여러 한정자끼리(특히 const와 volatile이) 비슷한 동작을 공유하기 때문에 별도 문단으로 분리했습니다. 예시는 const로 들겠습니다.
배열을 한정하는 문법은 없지만, const, volatile, restrict 모두 typedef를 이용해 배열을 한정할 수 있습니다. 이때의 동작은 표준 개정판에 따라 다릅니다.
- C23 이전: 모든 원소가 동일하게 한정되는 효과를 가집니다. 배열 자체는 한정되지 않습니다.
- C23 이후:
typedef와 상관없이 배열의 한정 여부와 원소의 한정 여부는 항상 같습니다.
typedef int Arr[8];
const Arr x = { 1, 2, 3, 4, 5, 6, 7, 8 };
x[4] = -5; // cannot assign to variable 'x' with const-qualified type 'const Arr' (aka 'int const[8]')
// ↑ 참고로 컴파일러에서 출력한 타입 이름 'int const[8]'은
// "a (const-qualified `[8]`) of `int`"를 의미합니다.
// 실제 코드에 위와 같이 쓰면
// "a `[8]` of `int const`로 인식됩니다.
함수를 한정하는 문법도 없으며, typedef를 이용해 함수를 const/volatile 한정하려고 하면 정의되지 않은 동작이 되고, restrict 한정하려고 하면 컴파일 오류가 발생합니다.
구조체나 공용체가 const/volatile 한정되었을 경우 모든 멤버가 동일하게 한정되는 효과를 가집니다.
struct Foo {
int x;
const int y;
};
struct Foo a = { 5, 6 };
const struct Foo b = { 7, 8 };
a.x = 9; // OK, int member of struct Foo
b.x = 10; // cannot assign to variable 'b' with const-qualified type 'const struct Foo'
const/volatile 한정되지 않은 타입의 포인터는 한정된 포인터에 대입할 수 있으며(변해도/최적화해도 되는 포인터를 변하지/최적화되지 않는 포인터에 대입), 그 역은 성립하지 않습니다(변하면/최적화되면 안 되는 포인터를 변할/최적화할 수 있는 포인터에 대입). 후자와 이중 이상의 포인터는 타입 변환을 해야 합니다.
int *p = NULL;
const int *q = p; // OK
p = q; // assigning to 'int *' from 'const int *' discards qualifiers
p = (int *)q; // well... OK
int **r = NULL;
const int **s = r; // initializing 'const int **' with an expression of type 'int **' discards qualifiers in nested pointer types
const/volatile 한정되었던 변수의 값에 한정되지 않은 포인터로 억지로 접근하려고 하면 정의되지 않은 동작이 됩니다.
const int x = 1;
*(int *)&x = 2; // undefined behavior
타입 변환
C를 쓰다 보면 원하든 원하지 않든 타입이 바뀌는 경우를 자주 볼 수 있습니다. 어떤 상황에서 무엇을 무엇으로 변환할 수 있고 어떻게 되는지를 정리해 보겠습니다.
암시적 변환
사용자가 명시적으로 (Type) 형태로 타입 변환을 하지 않는 경우입니다. 보통 산술 변환에서 unsigned를 선호하는 현상을 제외하면 대부분 상식 선에서 변환이 일어나고, 중요한 부분만 요약하자면 다음과 같습니다.
- 호환되는 타입끼리 암시적 변환이 된다.
- 산술 타입끼리 암시적 변환이 된다.
- 비
void와void포인터끼리 암시적 변환이 된다. - 0은 아무
NULL포인터로 암시적 변환이 된다. _Bool은 0과 같지만 않으면 무조건true로 변환된다.
암시적 변환이 일어나는 경우는 다음과 같이 세 종류입니다.
- 대입할 때처럼 변환[conversion as if by assignment]: 대입할 때나 이에 준하는 상황 (선언과 동시에 초기화, 인자 전달, 함숫값 반환)에 우변의 타입이 한정되지 않은 좌변으로 변환됩니다.
- 기본 인자 승급[default argument promotions]: 매개변수 목록이 없거나(K&R 스타일) 가변 인자 함수의
...부분에 해당하는 인자를 전달할 때 정수는 정수 승급을 거치고,float는double로 변환됩니다.float _Complex나float _Imaginary는 해당되지 않습니다.printf에서float와double을 구분 없이%f로 받을 수 있는 이유가 이것입니다.
- 보통 산술 변환[usual arithmetic conversions]: 산술 연산(
+,-,*,/,%), 비교(==,!=,<,>,<=,>=), 비트 단위 논리(&,|,^), 조건 연산자(?...:)를 사용할 때 양쪽의 타입이 다르면 둘 중 표현 범위가 더 큰 것으로 변환됩니다.
모든 암시적 변환은 아래와 같은 단계를 거치며, 상황에 따라 생략할 수 있습니다.
- 보통 산술 변환을 할 때는 공통된 타입을 먼저 찾습니다.
- 정수와 부동소숫점 타입 간에 연산할 경우 부동소숫점 쪽이 공통 타입이 됩니다.
- 부동소숫점 타입
long double이double보다,double이float보다 우선합니다.- 실수, 허수, 복소수 중 서로 다른 타입 간에 연산할 경우 복소수 타입이 됩니다.
- 정수 타입
- 우선 정수 승급을 거칩니다.
- 부호 여부가 같을 경우 (정수 승급 알고리즘상의) "등급"이 높은 타입이 공통 타입이 됩니다.
- 부호 여부가 다를 경우 부호가 있는 쪽을
S, 없는 쪽을U라고 하고...U의 "등급"이S이상일 경우S를U로 변환합니다.U의 "등급"이S미만이고U의 범위를S로 모두 표현할 수 있을 경우U를S로 변환합니다.- 그렇지 않을 경우
S에서 부호를 뗀 타입이 공통 타입이 됩니다.
- 좌측값이 비좌측값으로, 배열이 포인터로, 함수가 함수 포인터로 바뀝니다. 위에서 다룬 내용과 같으며, 좌측값 변환 도중에는 한정자와 원자성을 잃습니다.
- 아래에 제시되는 변환 방법 중 하나를 사용해서 원하는 타입으로 변환할 수 있다면 그 방법을 사용합니다.
- 호환되는 타입끼리: 아무것도 하지 않습니다.
- 정수 승급:
int이하의 정수 타입이int나unsigned int로 변환됩니다. 각 정수 타입의 "등급"은 부호 유무나 비트 필드 여부와 무관하게 표현 범위가 클수록 높고, 범위가 같을 경우 표준 타입(long long등. 64비트라고 가정합니다)이 같은 크기의 확장 타입(__int64등)보다 높습니다. _Bool로: 값이0과 같을 경우false, 그렇지 않을 경우true로 변환됩니다. 이때0.5나I(허수 단위) 등int로 변환했을 때 0이 되거나nan등이더라도 그 자체로 0이 아니라면true가 됩니다.- 실수(정수 포함), 복소수, 허수 간: 실수 부분과 허수 부분이 따로 변환됩니다. 실/허수 부분이...
- 없었다가 생길 경우 +0을 사용합니다.
- 있었다가 사라질 경우 그 값은 버립니다.
- 두 타입 모두에 있을 경우 실수/허수 상관없이 아래의 실수끼리 변환 규칙을 적용합니다.
- 실수끼리: 목표 타입이 기존 값을 정확하게 나타낼 수 있으면 그 값을 사용합니다. 그렇지 않을 경우 정수에서 실수로 변환할 때와 같습니다.
- 실수에서 정수로: 0 방향으로 버림한 값을 사용합니다(즉, 소숫점 아래를 버립니다). 목표 타입이 그 값을 표현하지 못할 때의 동작은 정의되지 않습니다.
- 정수에서 실수로: 실수 정밀도가 허용하는 한도 내에서 최대한 정밀하게 변환됩니다. 범위 초과 등의 이유로 변환할 수 없을 경우의 동작은 정의되지 않습니다.
- 정수끼리: 목표 타입이 기존 값을 나타낼 수 있으면 그 값을 사용합니다. 그렇지 않을 경우 목표 타입의 부호 유무에 따라...
- 부호 없는 정수: 목표 타입의 비트 수 \(b\)에 대해 \(\mathrm{mod} \; 2^b\)를 취합니다.
- 부호 있는 정수: 컴파일러마다 다르게 처리할 수 있습니다(implementation-defined).
- 포인터끼리
void *는 다른 모든 포인터와 변환할 수 있습니다.- 정의되지 않은 동작인 경우가 아니라면 기존 포인터를 변환했다가 돌려놓으면 그 포인터 값이 원래와 같아야 합니다. 이외에는 어떤 보장도 하지 않습니다.
- 한정자가 추가된 같은 타입의 포인터로 변환할 수 있고, 변환 전후의 포인터 값은 동일합니다. 역방향은 성립하지 않습니다.
- 정수 상수 0이나
(void *)0은 객체 타입과 함수 타입 상관 없이 아무 널 포인터로 변환할 수 있습니다. 역방향은 성립하지 않습니다.
명시적 변환
(Type) 연산자로 특정한 타입의 값을 다른 타입으로 변환할 수 있습니다. 중요한 부분만 요약하자면 다음과 같습니다.
- 암시적 변환이 된다면 명시적 변환도 된다.
(void)도 의외로 쓸 수 있다. "변환"된 값을 쓸 수는 없다.- 정수 타입과 포인터끼리 변환이 된다.
- 객체 타입의 포인터끼리 변환이 된다.
- 함수 포인터끼리 변환이 된다.
변환 규칙은 다음과 같습니다. 포인터끼리, 혹은 정수와 포인터 간에 정확히 어떻게 변환되는지는 표준에서 명시하지 않는다는 점에 유의해 주세요.
void로 "변환": 표현식을 평가만 하고 그 값은 버립니다.- 같은 타입으로: 아무것도 하지 않습니다.
- 대입할 때처럼 변환할 수 있으면 그 방법을 따릅니다.
- 그렇지 않을 경우, 아래에 제시된 변환 방법 중 하나를 사용할 수 있습니다.
- 정수에서 포인터로: 변환 방법과 결과는 컴파일러마다 다릅니다(implementation-defined).
- 포인터에서 정수로: 변환 방법과 결과는 컴파일러마다 다르며(implementation-defined), 널 포인터가 0으로 변환된다는 보장도 없습니다. 결과값을 목표 타입으로 나타낼 수 없을 경우의 동작은 부호 여부와 상관없이 정의되지 않습니다.
- 포인터끼리: 어느 쪽이든 널 포인터는 항상 널 포인터로 변환됩니다.
- 객체 타입의 포인터끼리 타입 제한 없이 변환할 수 있습니다. 정렬 상태가 잘못되어 있을 경우의 동작은 정의되지 않습니다. 아무 문자 타입의 포인터로 변환할 경우 그 객체의 가장 낮은 바이트를 가리키며, 이 방법으로 객체의 메모리상 표현을 읽거나 쓸 수 있습니다.
- 함수 포인터끼리 변환할 수 있습니다. 함수 포인터로 호환되지 않는 함수를 호출할 때의 동작은 정의되지 않습니다.
복합 리터럴 [compound literal] (C99~)
이 문단은 2021년 8월 20일에 추가로 작성했습니다.
선언문 바깥에서는 대괄호를 이용해 복합 타입에 대입할 수 없습니다.
struct Foo {
int foo;
} foo;
foo = { 123 }; // expected expression
이때는 대신 명시적 변환과 비슷한 문법을 이용해 대괄호 선언을 강제로 사용할 수 있습니다. 스칼라 타입, 복합 타입, 배열 타입(길이를 생략할 경우 대괄호 안쪽의 내용에서 추론합니다)을 모두 선언할 수 있습니다.
struct Foo { int foo; } foo;
foo = (struct Foo){ 123 }; // OK
printf("%d\n", foo.foo); // 123
int *bar;
bar = (int []){ 9, 99, 999 }; // OK, int [3]
printf("%d\n", bar[2]); // 999
int baz;
baz = (int){ 135 }; // OK
printf("%d\n", baz); // 135
복합 리터럴로 생성한 값은 좌측값이므로 변수에 대입하지 않아도 주소를 얻을 수 있습니다.
struct Foo { int foo; };
printf("%p\n", &(struct Foo){ 123 }); // OK
제네릭 선택 [generic selection] (C11~)
이 문단은 2021년 8월 20일에 추가로 작성했습니다.
C에도 의외로 타입 제네릭 연산을 지원하는 문법이 있습니다. _Generic() 안에 표현식('제어 표현식'이라고 합니다)과 타입에 따라 원하는 값을 넣으면 컴파일 시에 표현식의 타입을 확인해 일치하는 값으로 변환됩니다. 일치하는 타입이 없으면 컴파일 오류가 됩니다.
char *generic_test = _Generic(
123ll, // long long
int: "int",
long: "long",
long long: "long long"
); // ok, "long long"
char *generic_error = _Generic(
"troll",
int: "int"
); // controlling expression type 'char *' not compatible with any generic association type
제어 표현식은 다른 값과 같이 좌측값, 배열, 함수 변환을 거치기 때문에 한정자(스칼라 타입의 경우), 배열, 함수 타입은 사용할 수 없고 대신 포인터 타입을 사용해야 합니다.
void foo(int);
_Generic(
foo,
void (int): 1 // type 'void (int)' in generic association not an object type
);
int bar[3];
_Generic(
bar,
int [3]: 1
); // controlling expression type 'int *' not compatible with any generic association type
const int baz;
_Generic(
baz,
const int: 1
); // controlling expression type 'int' not compatible with any generic association type
const int quux(const int);
_Generic(
quux,
const int (*)(const int): 1 // 함수 자체가 아니라 매개변수와 반환값이 한정되었기 때문에 문제가 없습니다.
); // OK
이 문법 안에 들어간 모든 표현식은 일치하는 값을 제외하고 어느 것도 평가되지 않습니다.
int foo(char *msg, int result) {
printf("foo(\"%s\") called\n", msg);
return result;
}
int main() {
printf("%d\n", _Generic(
foo("controlling expression", 1),
int: foo("int", 2),
long: foo("long", 3),
long long: foo("long long", 4)
));
return 0;
}
// foo("int") called
// 2
일치하지 않는 나머지 타입을 잡아내려면 switch문과 비슷하게 default:를 사용할 수 있습니다.
printf("%d\n", _Generic(
(short)1,
int: 1,
long: 2,
long long: 3,
default: 99
)); // 99
제네릭 선택 문법은 #define 매크로 함수 안에 넣어서 쓸 수 있습니다. 다음은 cppreference에 올라온 예제를 들여쓰기와 주석만 수정한 것입니다.
#include <stdio.h>
#include <math.h>
// <tgmath.h> 매크로 함수 cbrt의 가능한 구현체
#define cbrt(X) _Generic((X),\
long double: cbrtl,\
default: cbrt,\
float: cbrtf\
)(X)
int main(void)
{
double x = 8.0;
const float y = 3.375;
// 기본값 cbrt를 선택함
printf("cbrt(8.0) = %f\n", cbrt(x)); // cbrt(8.0) = 2.000000
// const float를 float로 변환한 뒤 cbrtf를 선택함
printf("cbrtf(3.375) = %f\n", cbrt(y)); // cbrtf(3.375) = 1.500000
}
부록: 비주얼 스튜디오 서식 설정하기
이 문단은 2022년 4월 4일에 추가로 작성했습니다.
원래 이 글의 댓글에 답글로 추가했던 내용인데 본문에 넣는 것도 좋을 것 같네요.
비주얼 스튜디오는 포인터와 참조를 왼쪽 정렬(int* x;)하는 것으로 악명이 높습니다. 혹시나 제 글을 읽고 설득되셨다면, 비주얼 스튜디오 설정에서 포인터 정렬을 오른쪽으로 바꿀 수 있는 방법이 있습니다. 비주얼 스튜디오 2019/2022에 해당 설정이 있는 것을 확인했고 이전 버전에도 있는지는 잘 모르겠네요.
- 도구(T) - 옵션(O)...을 엽니다.
- 왼쪽 트리에서 텍스트 편집기 - C/C++ - 코드 스타일 - 서식 - 간격으로 들어갑니다.
- 포인터/참조 맞춤을 찾아 오른쪽 맞춤으로 변경합니다.
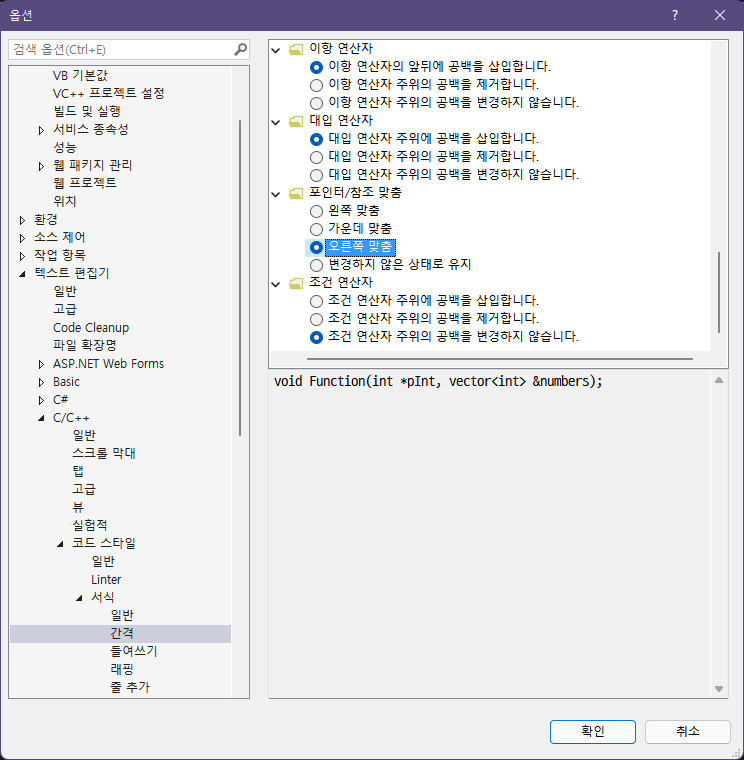
이외에도 세세한 서식 설정이 많으니 입맛대로 건드려보는 것도 좋겠습니다.
드디어 끝났네요!
원래 "int* x;는 틀리고 int *x;가 맞다"나 3번, 5번 떡밥만 얘기하고 끝내려고 했는데 파고들어가다 보니까 얼떨결에 타입 시스템을 통째로 다루게 됐네요.
이 글을 처음 쓰는 데 대충 열흘이 넘게 걸린 걸로 기억하고 있습니다. 물론 이것저것 조사하면서 긴 글을 쓰는 게 오랜만이라 힘들었지만 글쓴이인 저도 쓰면서 많은 것들을 배워갈 수 있었습니다. 글을 끝까지 읽어주신 여러분께도 무언가 남는 게 있었으면 좋겠네요! 감사합니다 🙇♂️
-
C17 개정판의 특성상 대표적인 C 컴파일러인 GCC와 Clang의 문서에는
__STDC_VERSION__매크로를 제외하고 모든 기능이 C17과 같다고 명시하고 있습니다. ↩ -
아래 게시물의 내용을 부연하자면, Dev-C++는 컴파일에 TDM-GCC를 씁니다. 이전 버전 Dev-C++는 딸려오는 TDM-GCC도 이전 버전인데(4.x.x), 이때는 플래그를 지정하지 않으면 C89 표준에 컴파일러 확장을 허용하여(
-std=gnu90) 컴파일을 했었습니다. ↩ -
identifier. 변수, 함수, 레이블 등을 가리키는 문자열을 의미합니다. ↩
-
function specifier. 함수에 부가적인 성질을 부여합니다.
inline은 컴파일러가 인라이닝을 해도 되는 함수,_Noreturn은exit나longjmp등의 이유로 인해 절대 반환하거나 끝까지 실행되지 않는 함수를 의미합니다. 이 글에서 자세히 다루지는 않겠습니다. ↩ -
variably-modified type. 원문의 의미를 유지하는 적당한 번역어가 없네요... ↩
-
optional chaining ↩
-
"
xis a[4]of[8]of*of*offloat" ↩ -
"
foois a*of(int [])of*ofint" ↩ -
"
zis a*of[123]of*of[456]of*of*ofchar" ↩ -
"
xis a*of(char *)of*of[64]of*ofint" ↩ -
lvalue. 메모리상에 "정체"가 있는 값을 말합니다. 다른 이유로 제한되는 경우가 아니면 대입하거나
&연산자로 주소를 얻을 수 있습니다. (역주) ↩ -
function designator (역주) ↩
-
jagged array. 각 행이 서로 다른 길이를 가질 수 있는 "배열(을 가리키는 포인터)의 배열" 자료구조를 말합니다. 그렇지 않은 "2차원 배열" 자료구조인 rectangular array에 대비됩니다. ↩
-
더 일반적으로는 C++에서
T를 반환하는 함수 타입으로도T의 생성자 호출로도 해석될 수 있는 모든 선언문은 반드시 후자로 해석되며, 이 현상에는 most vexing parse라는 이름이 있습니다. ↩ -
국어사전에서는 부작용을 "바람직하지 못한", "대개 좋지 않은 경우를 이"르는 것으로 정의하지만, 프로그래밍에서는 (주로 프로시저가) 인자를 받고 값을 반환하는 것 이외에 외부 환경에 영향을 미치는 경우를 말합니다. ↩
